![[kubernetes] Kubernetes Networking Model](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2F3YDZw%2FbtspokugmAG%2FAAAAAAAAAAAAAAAAAAAAAMfjsT-Fk_5nWmyMDM0XqzGcyKE4R4E5Vlhifz8yVF3U%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1753973999%26allow_ip%3D%26allow_referer%3D%26signature%3DyhTP1HFsbUkoDtm3HfEpHpTfuL0%253D)
해당 내용은 아래 포스팅 내용을 번역한 것입니다.
https://sookocheff.com/post/kubernetes/understanding-kubernetes-networking-model/
A Guide to the Kubernetes Networking Model
Kubernetes was built to run distributed systems over a cluster of machines. The very nature of distributed systems makes networking a central and necessary component of Kubernetes deployment, and understanding the Kubernetes networking model will allow you
sookocheff.com
The Kubernetes Networking Model
쿠버네티스는 모든 네트워킹 구현에 대해 다음 요구 사항을 지시한다.
- 모든 파드는 NAT(nerwork address translation)를 사용하지 않고 다른 파드들과 통신할 수 있다.
- 모든 노드는 모든 파드와 NAT 없이 통신할 수 있다.
- 파드가 자신을 보는 IP는 다른 사람이 보는 것과 동일한 IP이다.
이런 제약 조건을 감안할 때 해결해야 할 네 가지 고유한 네트워킹 문제가 있다.
- Container-to-Container networking
- Pod-to-Pod networking
- Pod-to-Service networking
- Internet-to-Service networking
1. Container-to-Container Networking
일반적으로 가상머신의 네트워크 통신은 이더넷 장치와 직접 상호작용 하는 것으로 간주된다.

실제로 상황은 더 복잡하다. Linux에서 실행중인 각 프로세스는 라우트, 방화벽 규칙, 네트워크 장치가 있는 논리적인 네트워킹 스택을 제공하는 네트워크 네임스페이스에서 통신한다.
본질적으로 네트워크 네임스페이스는 네임스페이스 내의 모든 프로세스에 대해 완전히 새로운 네트워크 스택을 제공한다.
일반적으로 리눅스는 외부 접근을 제공하기 위해 모든 프로세스를 루트 네트워크 네임스페이스에 할당한다.

도커 구조 측면에서, 파드는 네트워크 네임스페이스를 공유하는 도커 컨테이너 그룹으로 모델링된다.
파드 내의 모든 컨테이너는 파드에 할당된 네트워크 네임스페이스를 통해 할당된 동일한 IP주소와 포트공간을 갖는다. 그리고 동일한 네임스페이스에 상주하기 때문에 localhost를 통해 서로를 찾을 수 있다.
우리는 가상머신의 각 파드에 대한 네트워크 네임스페이스를 생성할 수 있다.

2. Pod-to-Pod Networking
쿠버네티스에서 모든 파드는 실제 IP 주소가 있으며 각 파드는 해당 IP 주소를 사용하여 다른 파드와 통신한다.
먼저, 하나의 노드에 존재하는 파드라고 가정하고 실제 IP를 사용하는 파드간 통신이 어떻게 이루어지는지 이해해보자.
각각의 파드는 다른 네트워크 네임스페이스에 존재한다. 그러나 네임스페이스들은 리눅스의 Virtual Ethernet Device 또는 veth pair를 사용하여 연결할 수 있다.
파드 네임스페이스를 연결하기 위해, veth pair의 한 쪽은 root 네트워크 네임스페이스에 할당하고 다른 한 쪽을 파드 네트워크 네임스페이스에 할당할 수 있다. 각 veth pair는 패치 케이블처럼 작동하여 양쪽을 연결하고 트래픽이 그들 사이에 흐를 수 있도록 한다.

파드가 각각 하나의 네트워크 네임스페이스를 가지므로써 자체 이더넷 장치와 IP 주소가 있다고 믿게됐고, 노드의 root 네임스페이스에 연결되도록 했다. 이제 파드가 root 네임스페이스를 통해 서로 통신하기를 원하며 이를 위해 네트워크 브리지를 사용한다.
Llinux 이더넷 브리지는 두 개 이상의 네트워크 세크먼트를 통합하는데 사용되는 가상 레이어 2 네트워킹 장치이다.
브리지는 통과하는 데이터 패킷의 대상을 검사하고 브리지에 연결된 다른 네트워크 세그먼트로 패킷을 전달할지 여부를 결정하여 원본과 대상 간에 포워딩 테이블을 유지 관리하여 작동한다.
- bridging code는 네트워크의 각 이더넷 장치의 고유한 MAC 주소를 확인하여 데이터르 브리지할지 삭제할지 결정한다.
- 브리지는 지정된 IP 주소와 연결된 MAC 주소를 찾기 위해 ARP 프로토콜을 구현한다.
- 브리지에 데이터 프레임이 수신되면, 브리지는 모든 연결된 장치로 프레임을 브로드캐스트(original sender를 제외하고)하고 프레임에 응답한 장치는 lookup테이블에 저장한다.
- 동일한 IP주소를 가진 트래픽은 lookup 테이블을 사용하여 패킷에 올바른 MAC 주소를 찾는다.

2.1. Life of a packet: Pod-to-Pod, same Node
독립된 파드의 네임스페이스, root 네임스페이스, 각각 연결된 가상 이더넷 장치, 네임스페이스를 연결해줄 브리지가 주어지면, 이제 같은 노드에서 파드간 트래픽을 전송할 준비가 완료되었다.
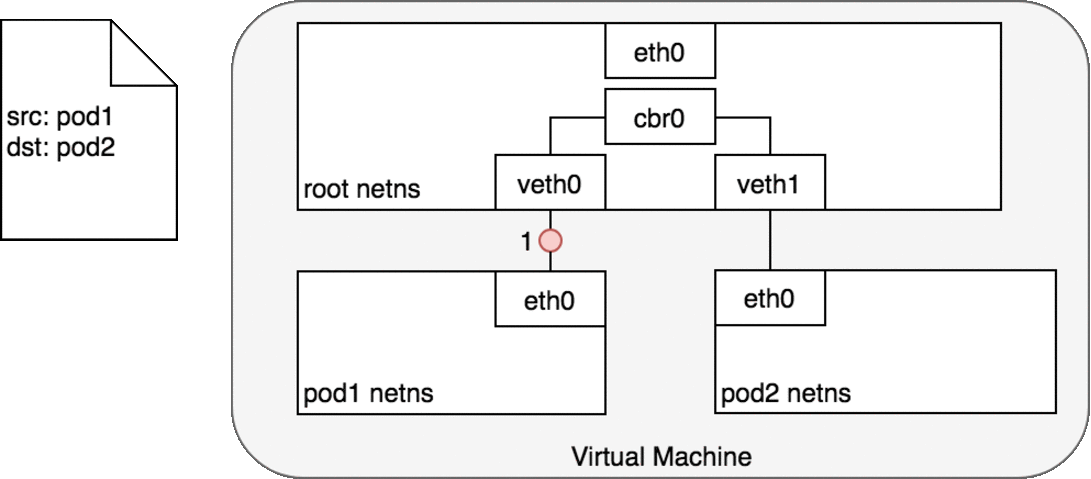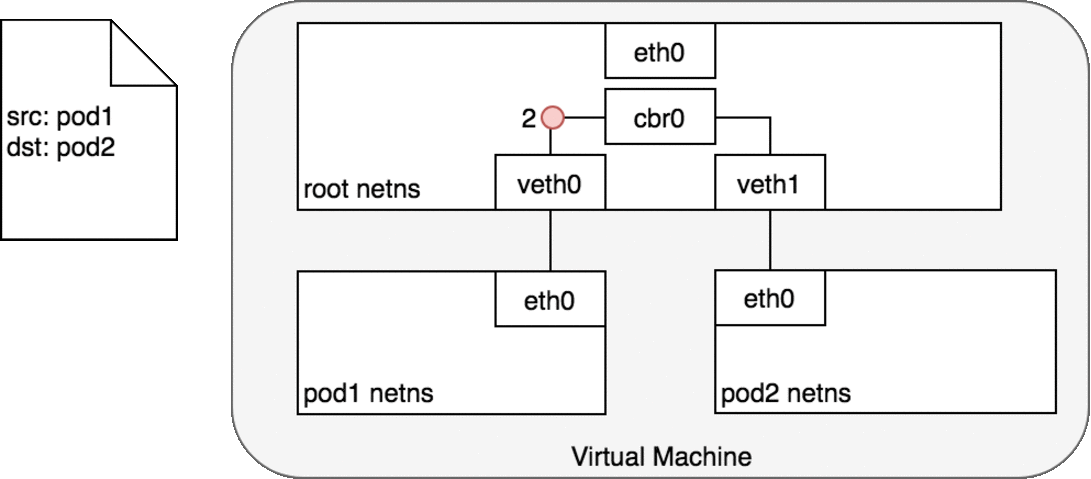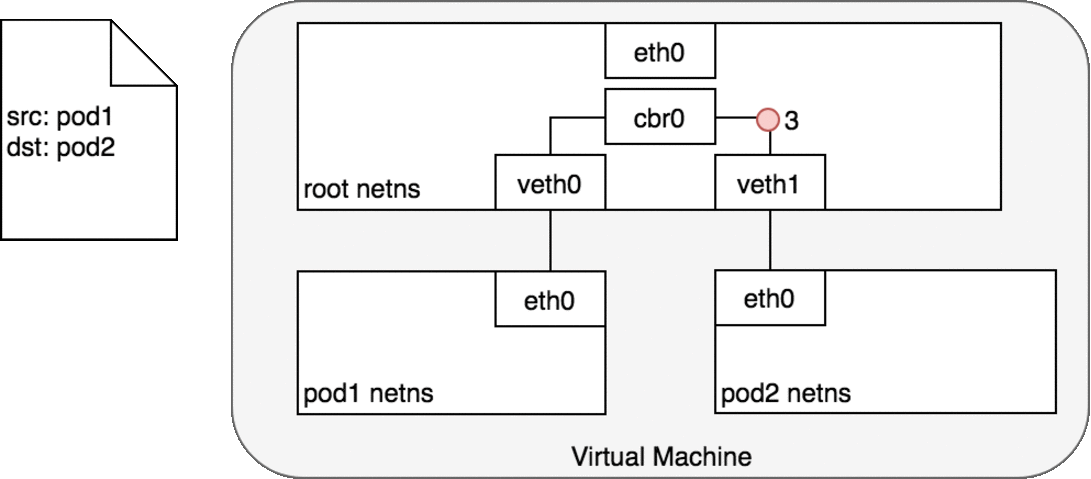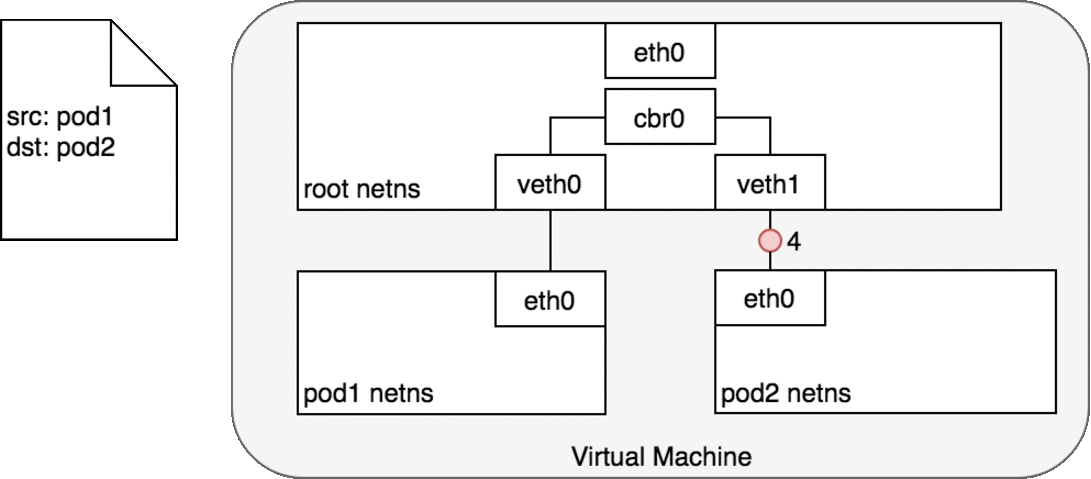
Figure 6. 에서, 파드1은 패킷을 자신의 이더넷 장치인 eth0으로 보낸다. eth0은 가상 이더넷 장치(veth0)를 통해 root 네임스페이스로 연결된다. 브리지 cbr0은 veth0에 연결된 네트워크 세크먼트로 구성된다. 패킷이 브리지에 도달하면, 브리지는 올바른 네트워크 세크먼트를 확인하여 ARP 프로토콜을 사용하여 veth1에 패킷을 보낸다.
패킷이 가상장치 veth1에 도달하면, 파드2의 네임스페이스와 해당 네임스페이스 내의 eth0 장치로 직접 전달된다. 이런 트래픽 흐름을 통해 각 파드는 오직 localhost에서 eth0과만 통신하고 트래픽은 올바른 파드로 라우팅된다.
2.2. Life of a packet: Pod-to-Pod, across Node
일반적으로 클러스터의 모든 노드에는 해당 노드에서 실행되는 파드에서 사용할 수 있는 IP 주소를 지정하는 CIDR 블록이 할당된다.
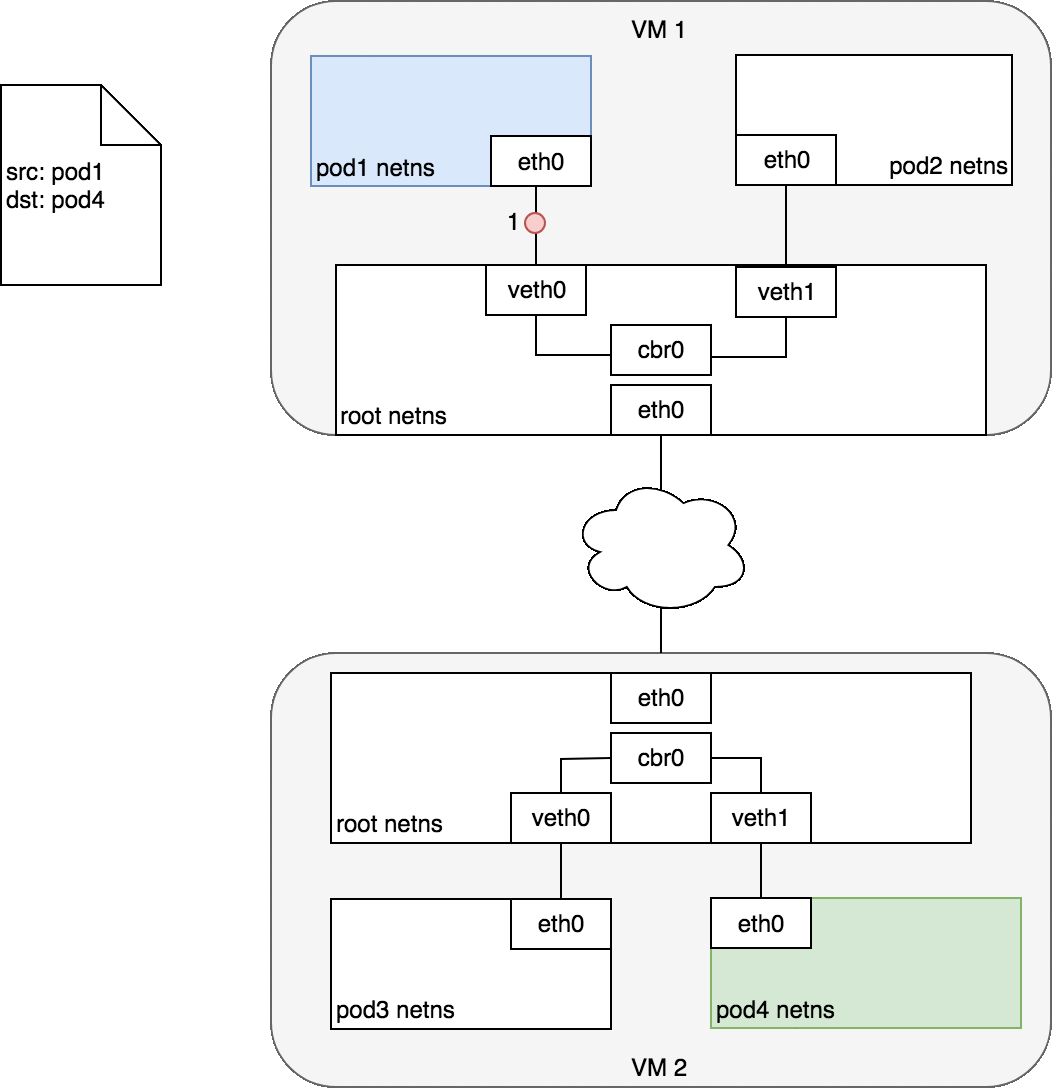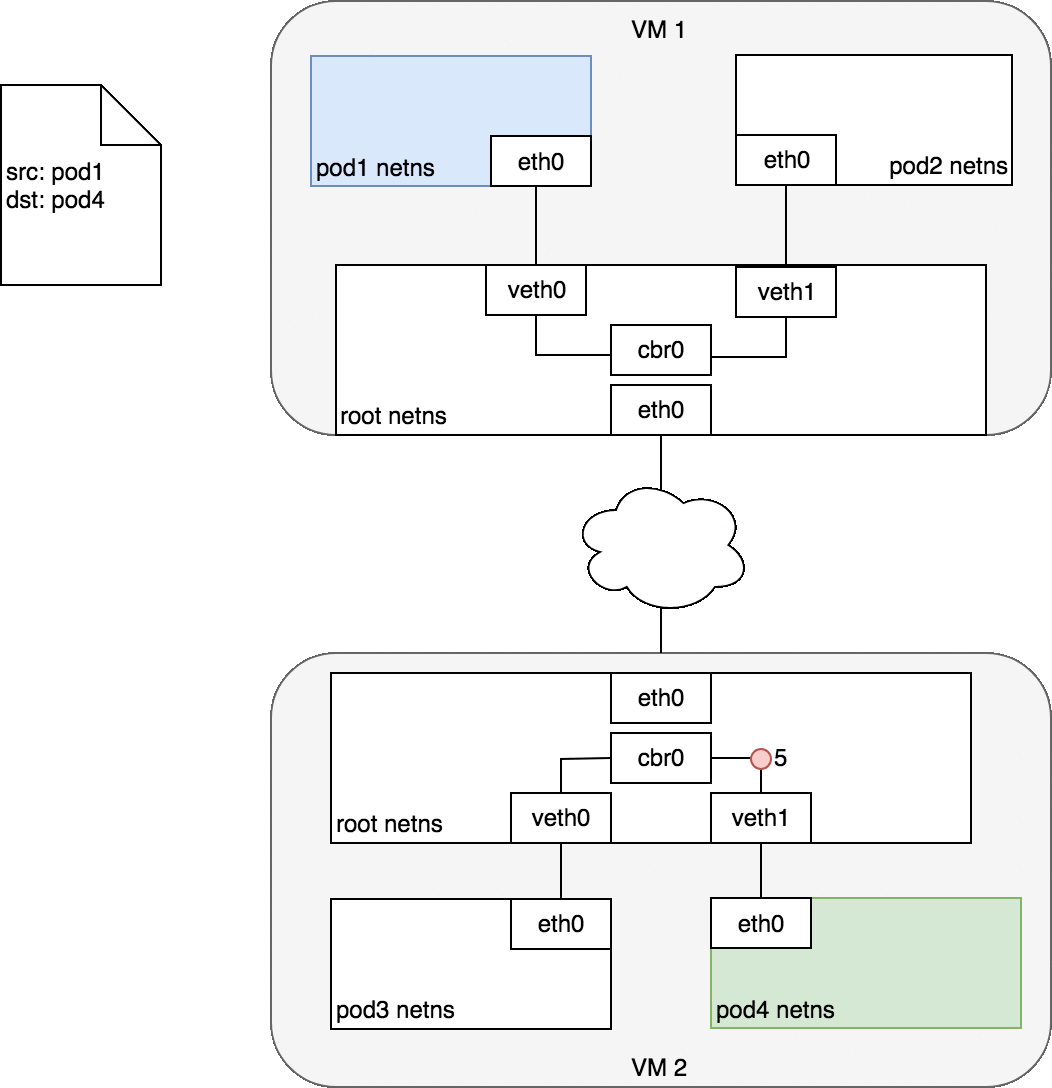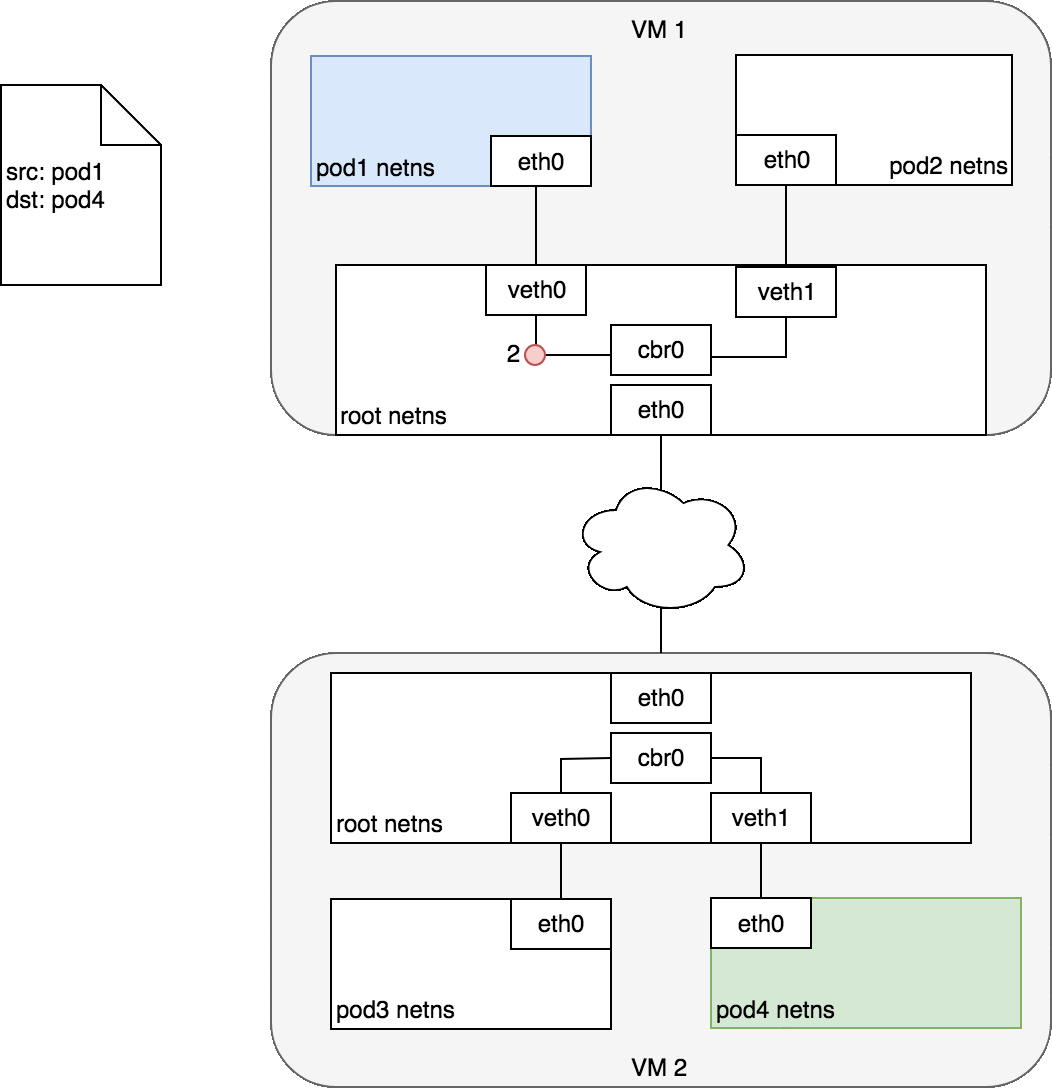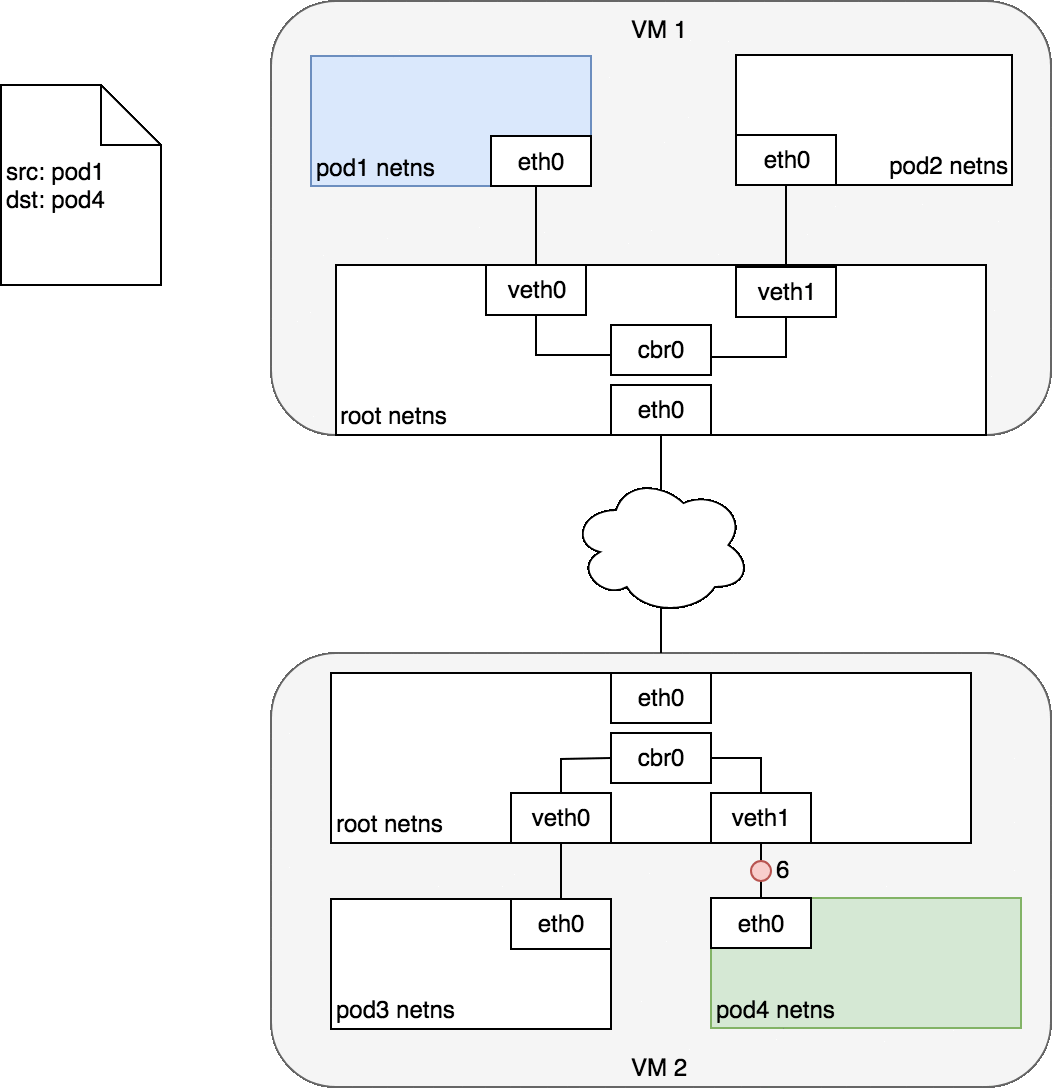
그림 7은 그림 6과 동일하지만 소스 파드(파란색)가 대상 파드(초록색)와 다른 노드에 있다.
패킷은 파드1의 이더넷 장치를 통해 전송되는 것으로 시작한다.
패킷은 루트 네임스페이스의 네트워크 브리지에서 끝난다. 브리지에 연결된 올바른 MAC 주소를 가진 장치가 없기 때문에 ARP는 브리지에서 실패할 것이다. 실패하면, 브리지는 패킷을 기본경로인 root 네임스페이스의 eth0 장치로 보낸다. (이 시점에서 라우트는 노드를 떠나 네트워크로 들어간다. 지금은 네트워크가 노드에 할당된 CIDR 블록을 기반으로 올바른 노드로 패킷을 라우팅할 수 있다고 가정한다.)
패킷은 대상 노드의 root 네임스페이스(VM2의 eth0)로 들어가고 여기서 브리지를 통해 올바른 가상 이더넷 장치로 라우팅된다.
마지막으로 파드4의 네임스페이스에 있는 가상 이더넷 장치 쌍을 통해 라우트가 완료된다.
해당 글에서는 IP를 올바른 노드로 중개하는 방법을 회피했다. CNI을 통해 해당 기능을 사용할 수 있으며 CNI(Container Network Interface)는 컨테이너를 외부 네트워크에 연결하기 위한 공통 API를 제공한다.
3. Pod-to-Service Networking
서비스는 파드에 대한 추상화 역할을 하며 가상 IP주소를 파드IP 주소 그룹에 할당한다. 그렇기 때문에 파드의 IP주소가 변경돼도 클라이언트 입장에서는 변경되지 않는 서비스의 가상IP만 알면 된다.
쿠버네티스 서비스를 생성할 때 가상IP(ClusterIP)가 자동으로 생성된다. 가상IP로 주소가 지정된 트래픽은 서비스와 연결된 파드로 로드밸런싱된다. 쿠버네티스는 트래픽을 서비스와 연결된 파드에 분산하는 인클러스터 로드밸런서를 자동으로 생성하고 유지한다.
3.1. netfilter and iptables
클러스터내에서 로드밸런싱을 수행하기 위해 쿠버네티스는 리눅스에 내장된 네트워킹 프레임워크인 netfilter를 사용한다.
netfilter는 패킷 필터링, 네트워크 주소 변환 및 포트 변환을 위한 다양한 기능과 작업을 제공한다.
이러한 기능은 네트워크를 통해 패킷을 전달할 수 있도록 하고 네트워크 내의 중요한 위치에 도달하지 못하도록 하는 기능을 제공한다.
iptables는 netfilter 프레임워크를 사용하여 패킷을 조작하고 변환하기 위한 규칙을 정의하는 테이블 기반 시스템을 제공하는 프로그램이다.
쿠버네티스에 iptables 규칙은 API server의 변경사항을 감시하는 kube-proxy 컨트롤러에 의해 구성된다.
서비스 또는 파드에 대한 변경 사항으로 인해 서비스의 가상IP 또는 파드의 IP주소가 업데이트 되면 iptables 규칙이 업데이트되어 서비스로 향하는 트래픽을 파드로 올바르게 라우팅한다.
iptables는 서비스의 IP로 향하는 트래픽을 실제 파드 IP로 연결하기 위해 시스템에서 로드밸런싱을 수행했다.
3.2. IPVS
쿠버네티스의 최신 릴리즈(1.11)에는 클러스터 내 로드밸런싱을 위한 두 번째 옵션인 IPVS가 포함되어있다.
IPVS(IP 가상 서버)도 netfilter 위에 구축되며 리눅스 커널의 일부로 전송계층 로드밸런싱을 구현한다.
IPVS는 LVS(리눅스 가상 서버)에 통합되어 호스트에서 실행되며 실제 서버 클러스터 앞에서 로드밸런서 열할을 한다.
IPVS는 TCP 및 UDP 기반 서비스에 대한 요청을 실제 서버로 보낼 수 있으며 실제 서버의 서비스가 단일 IP 주소에서 가상 서비스로 나타나도록 할 수 있다.
따라서 IPVS는 쿠버네티스 서비스에 자연스럽게 적합하다.
쿠버네티스 서비스를 선언할 때 iptables 또는 IPVS를 사용하여 클러스터 내 로드벨런싱을 수행할지 여부를 지정할 수 있다.
IPVS는 로드밸런싱을 위해 특별히 설계되었으며 보다 효율적인 데이터 구조를 사용하므로 iptables에 비해 거의 무제한 확장이 가능하다.
3.3. Life of a packet: Pod to Service

파드와 서비스간 패킷 라우팅 시 여정은 이전과 동일한 방식으로 시작된다.
eth0 패킷은 먼저 파드의 네트워크 네임스페이스에 연결된 인터페이스를 통해 파드를 나간다. 그 후 가상 이더넷장치를 통해 브리지로 이동한다.
브리지에서 실행되는 ARP 프로토콜은 서비스에 대해 알지 못하므로 기본 경로 eth0을 통해 패킷을 전송한다.
여기서 추가적인 일이 발생하는데, eth0에서 패킷을 받기 전에, 패킷을 iptables를 통해 필터링 된다.
패킷을 수신한 후 iptables는 서비스 또는 파드 이벤트에 대한 응답으로 kube-proxy가 노드에 설치한 규칙을 사용하여 패킷의 대상을 서비스 IP에서 특정 파드 IP로 다시 쓴다.
패킷은 이제 서비스의 가상 IP가 아닌 파드4에 도달하도록 지정되었다.
3.4. Life of a packet: Service to Pod
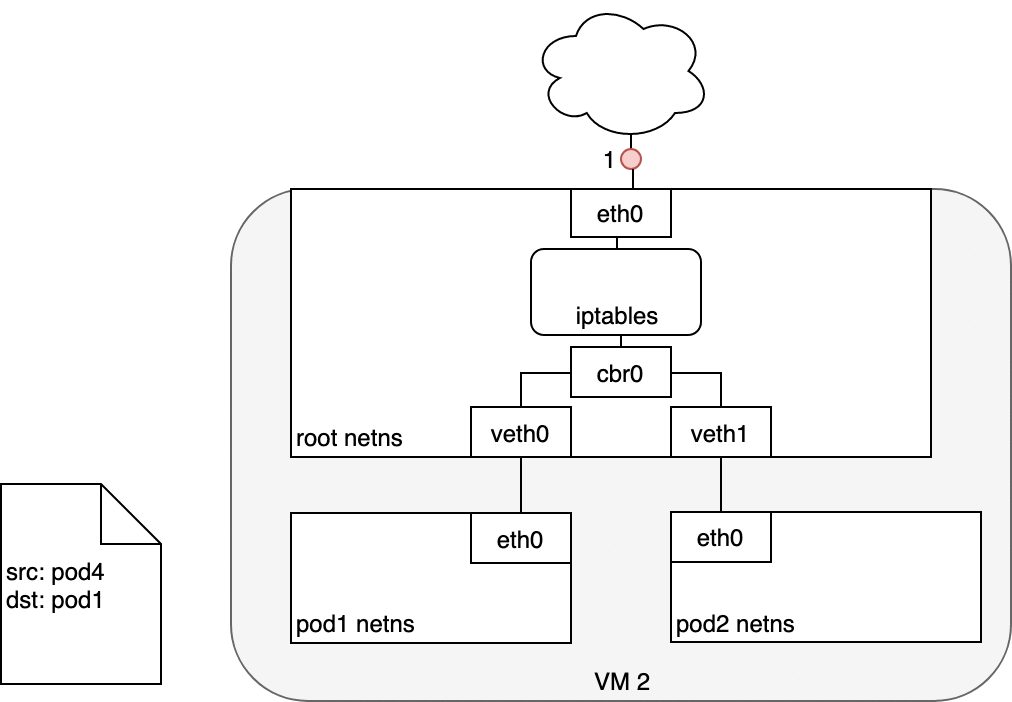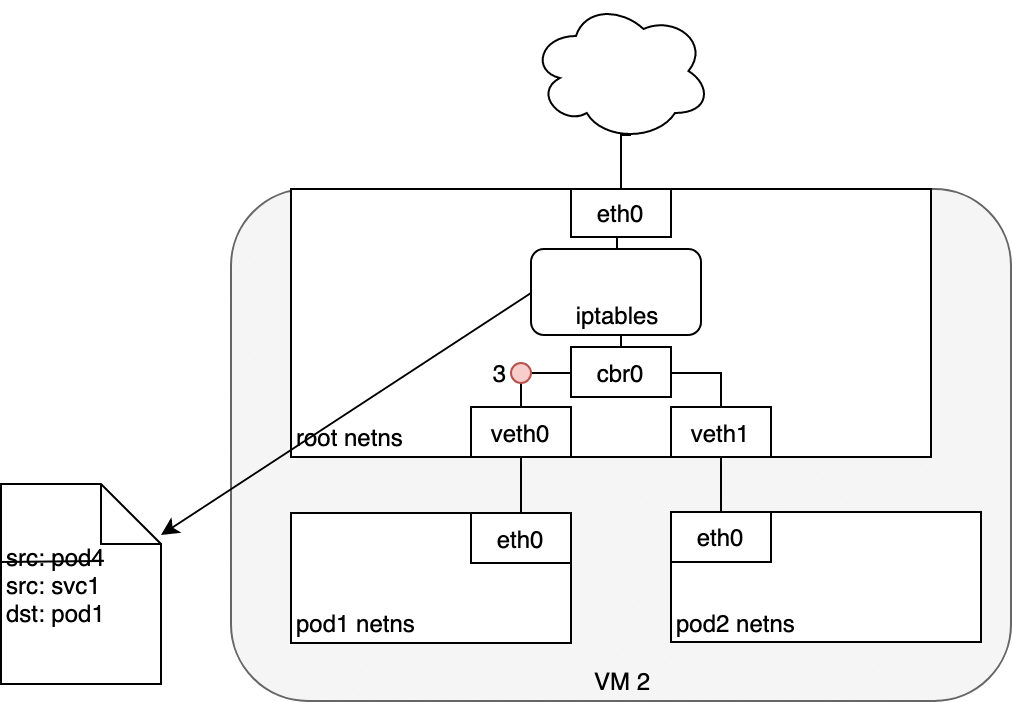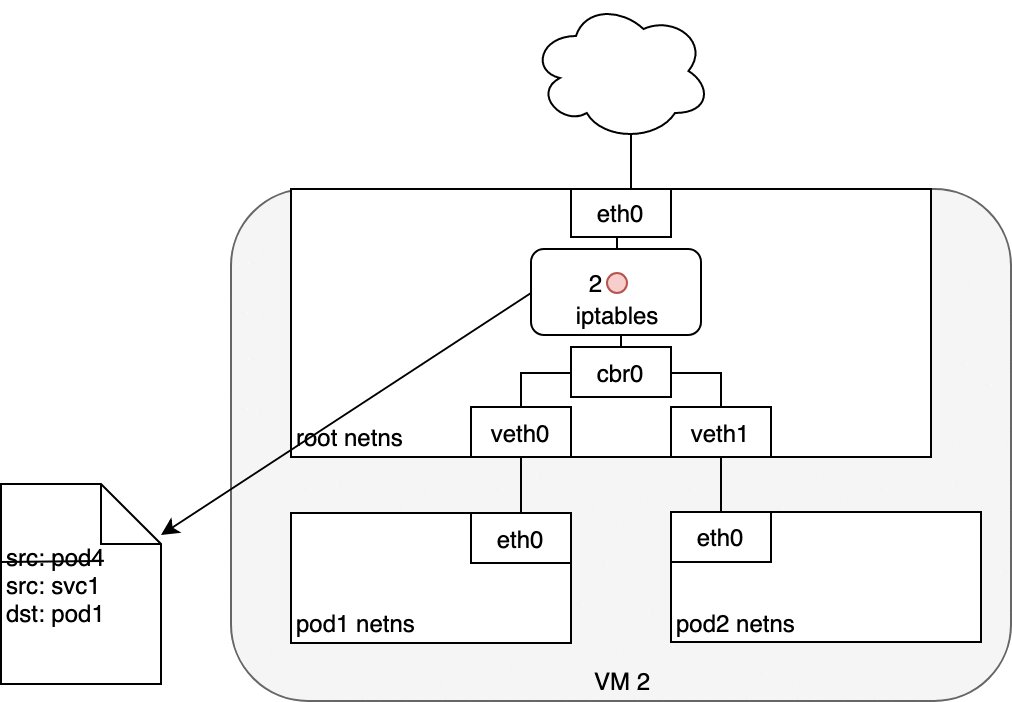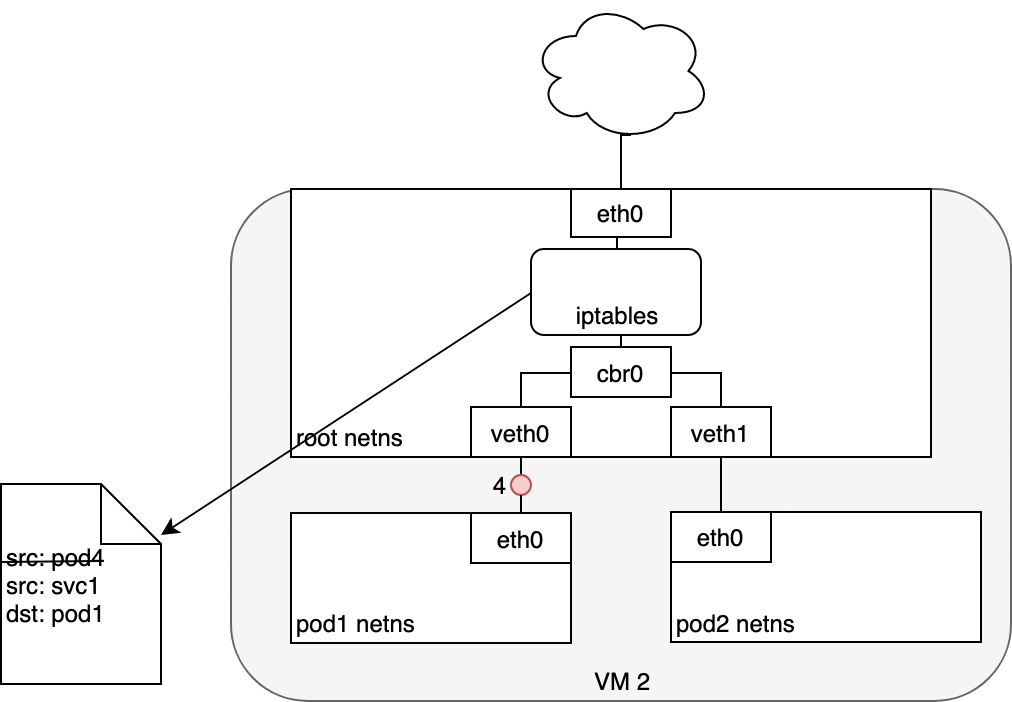
3.5. Using DNS
쿠버네티스는 선택적으로 DNS를 사용하여 서비스의 클러스터 IP주소를 애플리케이션에 하드코딩하지 않아도 된다.
쿠버네티스 DNS는 클러스터에 스케줄된 일반적인 쿠버네티스 서비스로서 실행된다.
컨테이너가 DNS 서비스IP를 사용하여 DNS이름을 확인하도록 각 노드에서 kubelet을 구성한다.
클러스터에 정의된 모든 서비스에는 DNS이름이 할당된다.
DNS 레코드는 필요에 따라 서비스의 클러스터 IP 또는 파드의 IP로 DNS 이름을 확인한다.
DNS파드는 세 개의 개별 컨테이너로 구성된다.
- kubedns: 서비스 및 엔드포인트 변경 사항을 감시하고 메모리 내 lookup 구조를 유지하여 DNS 요청을 처리한다.
- dnsmasq: 성능 향상을 위해 DNS 캐싱을 추가한다.
- sidecar: dnsmasq 및 kubedns에 대한 상태 확인을 수행하기 위해 단일 상태 확인 엔드포인트를 제공한다.
kubedns는 etcd 저장소를 DNS 전체로 변환하는 라이브러리를 사용하여 필요할 때 메모리 내 DNS 조회구조의 상태를 재구성한다.
CoreDNS는 kubedns와 유사하게 작동하지만 더 유연하게 만드는 플러그인 아키텍처로 구축된다.
쿠버네티스 1.11부터 CoreDNS는 쿠버네티스의 기본 DNS이다.
4. Internet-to-Service Networking
지금까지 쿠버네티스 클러스터 내에서 트래픽이 라우팅되는 방식을 살펴보았다. 쿠버네티스 서비스에서 인터넷으로 트랙픽을 가져오는 방법과 인터넷에서 쿠버네티스 서비스로 트래픽을 가져오는 두 가지 방법을 살펴보자.
4.1. Egress — Routing traffic to the Internet
다음 그림에서 패킷은 파드의 네임스페이스에서 시작하여 root 네임스페이스에 연결된 veth 쌍을 통해 이동한다.
패킷의 IP가 브리지에 연결된 네트워크 세그먼트와 일치하지 않기 때문에 root 네임스페이스에 eth0으로 이동한다.
root 네임스페이스의 이더넷 장치에 도달하기 전에 iptables는 패킷을 맹글링한다.
게이트웨이 NAT가 VM에 연결된 IP주소만 인식하기 때문에 패킷의 소스IP 주소를 파드로 유지하면 인터넷 게이트웨이는 이를 거부한다.
해결책은 패킷이 파드가 아닌 VM에서 오는 것처럼 보이도록 iptables가 소스NAT(패킷 소스 변경)를 수행하도록 하는 것이다.
올바른 소스 IP가 있으면 이제 패킷이 VM을 떠나 인터넷 게이트웨이에 도달할 수 있다.
인터넷 게이트웨이는 소스 IP를 VM 내부 IP에서 외부 IP로 재작성하는 또 다른 NAT를 수행한다.
마지막으로 패킷은 공용 인터넷에 도달한다.

4.2. Ingress — Routing Internet traffic to Kubernetes
트래픽을 클러스터로 가져오는 인그레스는 해결하기 매우 까다로운 문제이다.
일반적으로 네트워크 스택의 서로 다른 부분에서 작동하는 (1) Service LoadBalancer 및 (2) Ingress Controller로 나뉜다.
4.2.1. Layer 4 Ingress: LoadBalancer
쿠버네티스 서비스를 생성할 때 로드밸런서를 선택적으로 지정할 수 있다.
로드밸런서의 구현은 서비스에 대한 로드밸런서를 생성하는 방법을 알고 있는 cloud controller에서 제공한다.
서비스가 생성되면 로드밸런서의 IP주소를 알린다. 사용자는 로드밸런서로 트래픽을 전달하여 서비스와 통신을 시작할 수 있다.
4.2.2. Life of packet: LoadBalancer to Service
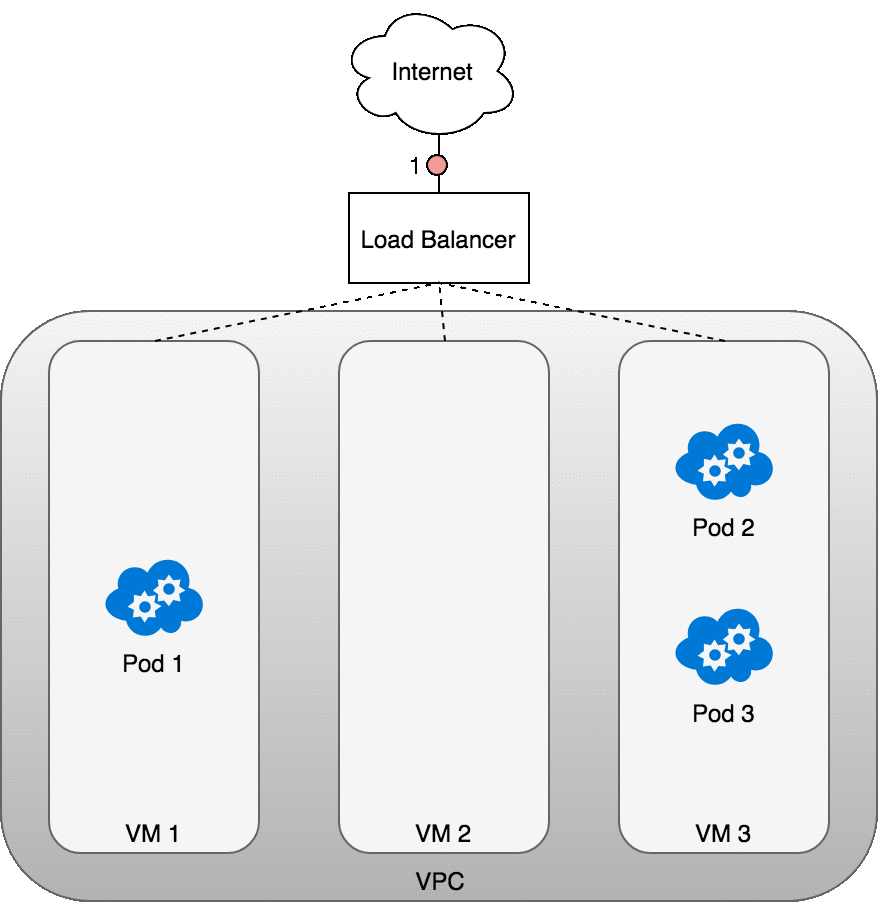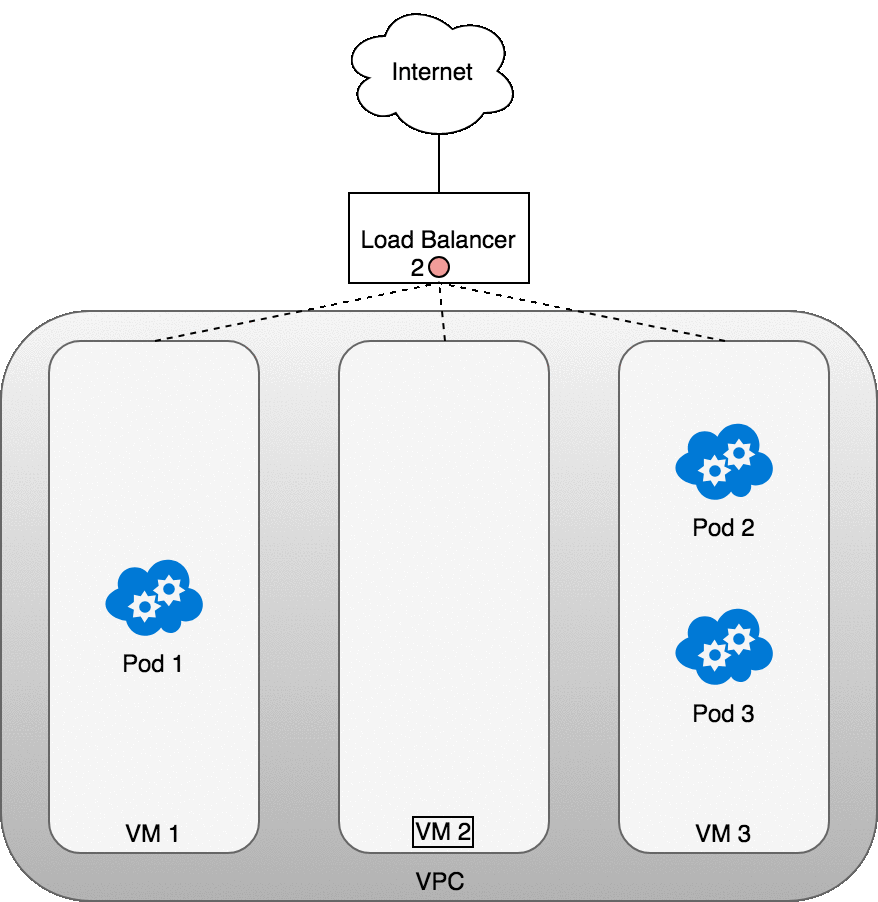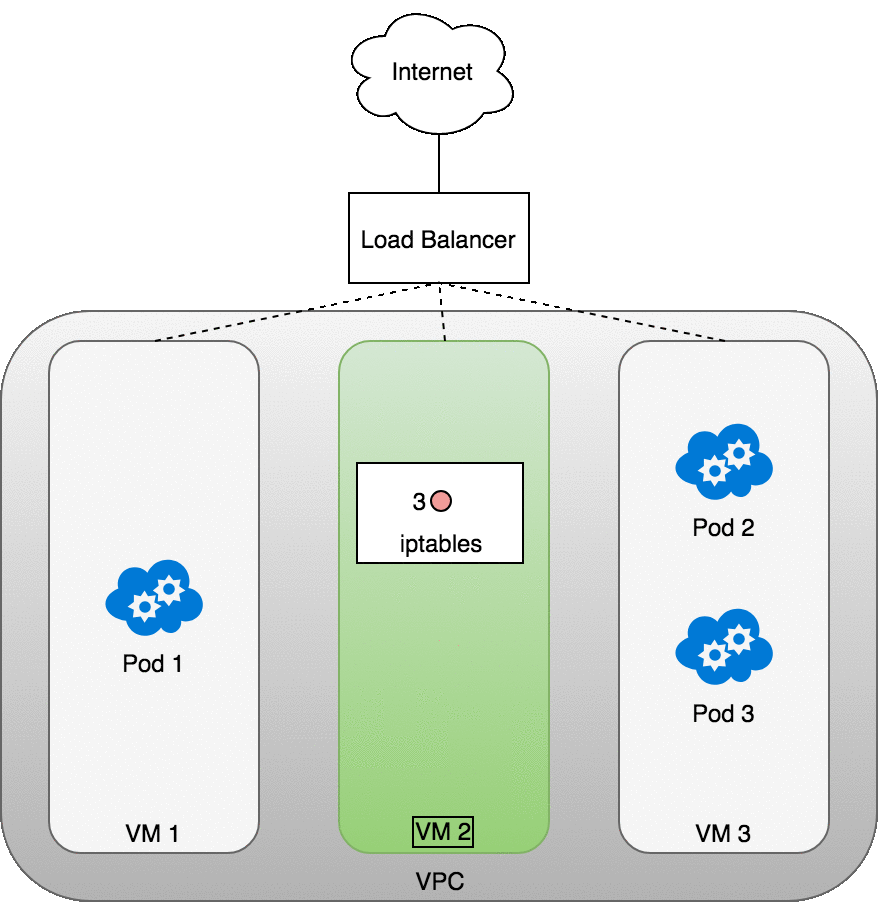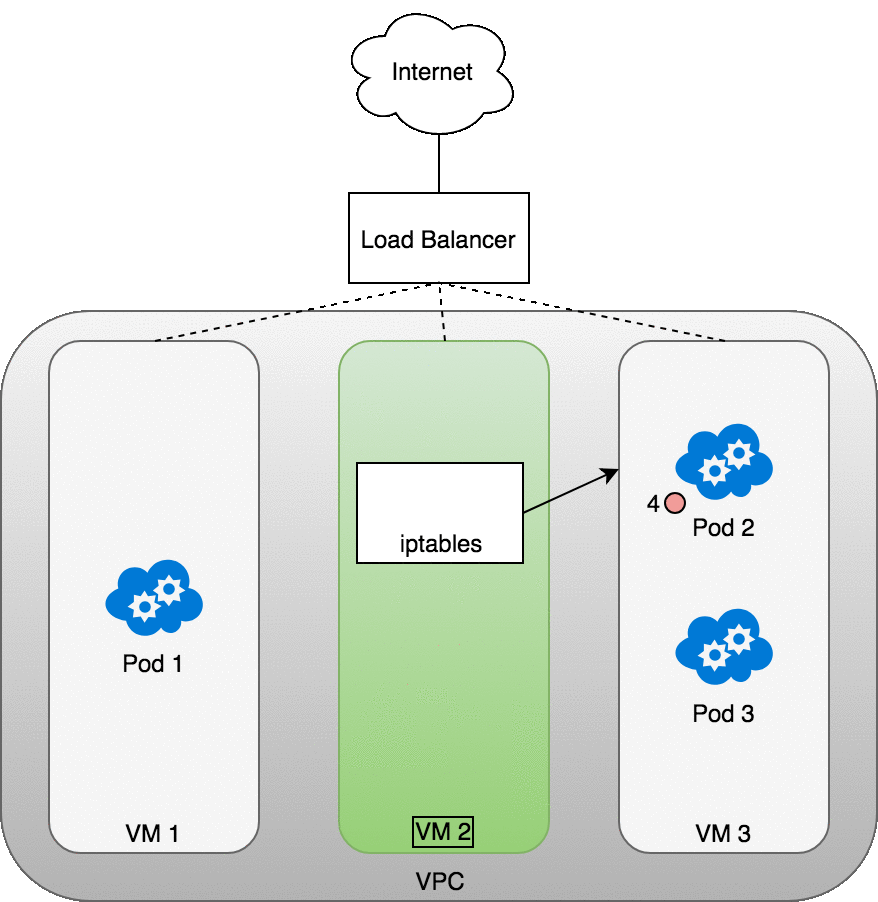
다음 그림은 파드를 호스팅하는 3개의 VM 앞에 있는 네트워크 로드밸런서를 보여준다.
들어오는 트래픽은 서비스의 로드밸런서로 전달된다. 로드밸런서가 패킷을 수신하면 무작위로 VM을 선택한다.
이 경우 파드가 존재하지 않는 VM2를 선택했다.
여기서 VM에서 실행되는 iptables 규칙은 kube-proxy를 사용하여 클러스터에 설치된 내부 로드밸런싱 규칙을 사용하여 패킷을 올바를 파드로 보낸다. iptables는 올바른 NAT를 수행하고 패킷을 올바른 파드로 전달한다.
4.2.3. Layer 7 Ingress: Ingress Controller
Layer7 네트워크 Ingress는 HTTP/HTTPS 프로토콜 범위에서 작동하며 서비스 위에 구축된다.
Ingress를 활성화하는 첫 번째 단계는 쿠버네티스에서 서비스 유형을 사용하여 서비스에서 NodePort를 여는 것이다.
노드의 포트로 향하는 모든 트래픽은 iptables 규칙을 사용하여 서비스로 전달된다.
노드의 포트를 인터넷에 노출하려면 Ingress 객체를 사용한다.
Ingress는 HTTP 요청을 쿠버네티스 서비스에 매핑하는 상위 수준의 HTTP 로드밸런서이다.
Ingress 방법은 kubernetes cloud provider controller에서 구현하는 방법에 따라 달라진다.
Layer4 네트워크 로드밸런서는 노드 IP만 이해하므로 트래픽 라우팅은 kube-proxy가 각 노드에 설치한 iptables 규칙에서 제공하는 내부 로드밸런싱을 활용한다.
4.2.4. Life of a packet: Ingress to Service
Ingress를 통해 흐르는 패킷의 수명은 로드밸런서의 수명과 매우 유사하다.
주요 차이점은 Ingress가 URL의 경로를 인식하고(해당 경로를 기반으로 서비스에 트래픽을 허용하고 라우팅할 수 있음) Ingress와 노드간의 초기 연결이 각 서비스에 대해 노드에 노출된 포트를 통해 이루어진다는 점이다.

Layer7 로드밸런서의 이점은 HTTP를 인식하므로 URL및 경로에 대해 알고있다는 것이다.
이렇게 하면 URL 경로 별 서비스 트래픽을 분할할 수 있다.
'클라우드 > Kubernetes(쿠버네티스)' 카테고리의 다른 글
| [kubernetes] pod lifecycle (0) | 2023.08.10 |
|---|---|
| [kubernetes] kube-proxy (0) | 2023.08.03 |
| [kubernetes] mac m1 kubernetes 구축 (2) | 2022.07.31 |
| kanico 란 (0) | 2022.05.29 |
| [kubernetes] 쿠버네티스 아키텍처 (0) | 2021.09.25 |