
0. MongoDB에 크롤링 데이터 저장하기
- Database, Collection 생성
- db : movie_db, col : actor_col
- data/actors.json file을 읽어서 처리하기
# warning 감추기
import warnings
warnings.filterwarnings(action='ignore')
import pymongo
import json
# 1. connection 생성
conn = pymongo.MongoClient('localhost',27017)
print(conn)
# 2. database 생성
movie = conn.movie_db
print(movie)
print(movie.name)
# 3. collection 생성
actors = movie_db.actor_col
print(actors)
# 4.json file open
with open('data/actors.json','r',encoding='utf-8') as file:
json_data = json.load(file)
actors.insert_many(json_data)
# document count
print(actors.estimated_document_count())

1. sort
# 기본적으로 ascending
docs = actors.find({}).sort('배우이름')
# descending
docs = actors.find({}).sort('배우이름',pymongo.DESCENDING)
# sort by multiple field
docs = actors.find({}).sort([('배우이름',pymongo.ASCENDING),('랭킹',pymongo.DESCENDING)])
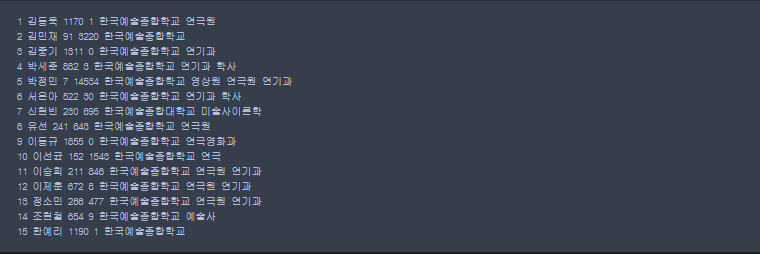
docs = actors.find({'학교':{'$regex':'한국예술'}}).sort('배우이름')
for idx,actor in enumerate(docs,1):
print(idx,actor['배우이름'],actor['랭킹'],actor['흥행지수'],actor['학교'])
2. exists
- 필드값이 존재하는 경우에 한해서 검색
# '특기' 필드가 존재하는 경우와 존재하지 않는 경우 count
print(actors.find({'특기':{'$exists':True}}).count())
print(actors.find({'특기':{'$exists':False}}).count())

# '생년월일' 이 있는 배우의 이름과 생년월일
# find({},{'배우이름':1,'생년월일':1,'_id':0})
docs = actors.find({},{'배우이름':1,'생년월일':1,'_id':0})
docs = actors.find({'생년월일':{'$exists':True}})
for actor in docs:
print(actor['배우이름'],actor['생년월일'])

# '다른 이름'이 '조원준'인 배우의 이름, 랭킹, 다른이름을 출력하시오
docs = actors.find({'다른 이름':{'$exists':True},'다른 이름':'조원준'})
for actor in docs:
print(actor['배우이름'],actor['랭킹'],actor['다른 이름'])

3. 필드의 범위로 검색
- $gt, $gte
- $lt, $lte
# 흥행지수 10000 <= 흥행지수 <= 30000 배우를 검색
# count()
# 배우이름:1, 흥행지수:1, 출연영화:1, _id:0
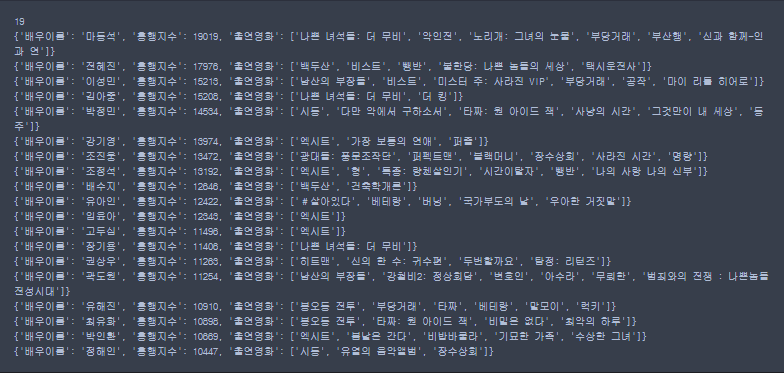
filter = {'흥행지수':{'$gte':10000,'$lte':30000}}
fields = {'배우이름':1,'흥행지수':1,'출연영화':1,'_id':0}
print(actors.find(filter).count())
for actor in actors.find(filter,fields):
print(actor)
4. or, nor (not or)
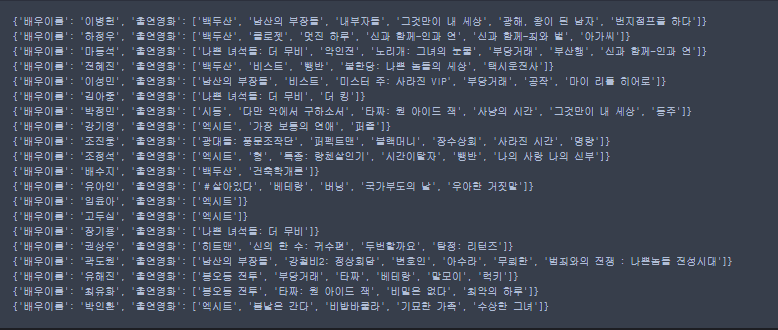
# 흥행지수가 >= 15000 이거나 랭킹 <= 20 인 배우이름과 출연영화 리스트 출력하기
filter = {'$or':[{'흥행지수':{'$gte':15000}},{'랭킹':{'$lte':20}}]}
fields = {'배우이름':1,'출연영화':1,'_id':0}
for actor in actors.find(filter,fields):
print(actor)
# $nor
# 흥행지수 >= 15000, 성별 = 남
match = {'$nor':[{'흥행지수':{'$lte':15000}},{'성별':'여'}]}
fields = {'배우이름':1,'성별':1,'흥행지수':1,'_id':0}
print(actors.find(match).count())
for actor in actors.find(match,fields):
print(actor)

5. $sortByCount
- aggregate() 함수 사용
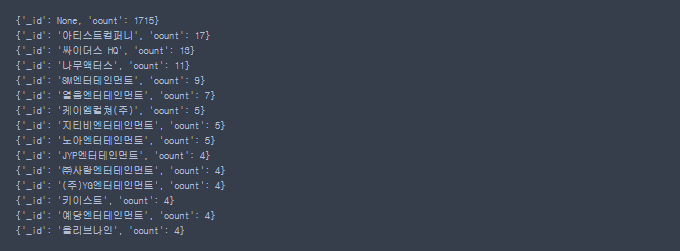
# 소속사별 count
match = [{'$sortByCount':'$소속사'}]
match = [{'$sortByCount':'$소속사'},{'$match':{'count':{'$gte':4}}}]
for actor in actors.aggregate(match):
print(actor)
6. list 검색
- 리스트 안에 들어 있는 내용을 검색하기 위해서는 순서와 값이 정확이 일치해야 함
- 순서에 상관없이 값으롼 찾으려면 $all 를 사용한다.
# 출연영화 리스트에 '반도'를 포함하는 경우
match = {'출연영화':'반도'}
# 출연영화 리스트에 '1987' 또는 '반도'를 포함하는 경우
match = {'$or':[{'출연영화':'1987'},{'출연영화':'반도'}]}
# 출연영화 리스트에 '남산의 부장들'과 '공작'을 포함하는 경우
match = {'출연영화':['남산의 부장들','공작']} #조건에 만족하지 않는다. '남산의 부장들' 다음에 바로 '공작' 이 나오지 않으면 출력 안됨
# $all 사용
match = {'출연영화':{'$all':['남산의 부장들','공작']}}
# 출연 영화의 첫번째 요소가 '결백'인 경우
match = {'출연영화.0':'결백'}
# 출연 영화의 두번째 요소가 '밀양'인 경우
match = {'출연영화.1':'밀양'}
# 출연 영화의 갯수가 6편인 경우
match = {'출연영화':{'$size':6}}
fields = {'배우이름':1, '출연영화':1, '_id':0}
for actor in actors.find(match,fields):
print(actor)

7. limit()
# 직업이 가수이면서 흥행지수가 높은 상위 10명의 배우는?
for actor in actors.find({'직업':'가수'}).sort('흥행지수',pymongo.DESCENDING).limit(10):
print(actor)

# '국가부도의 날' 에 출연한 배우를 흥행지수가 높은 순으로 10명을 출력하시오
# _id만 빼고
for actor in actors.find({'출연영화':'국가부도의 날'},{'_id':0}).sort('흥행지수',pymongo.DESCENDING).limit(10):
print(actor)

'데이터베이스 > MongoDB' 카테고리의 다른 글
| MongoDB aggregate 연습문제 (0) | 2020.07.31 |
|---|---|
| MongoDB 집계함수 (0) | 2020.07.30 |
| MongoDB 설치 (0) | 2020.07.29 |