
Pandas
1. iloc[] 사용(원하는 index줘서 선택)
** data/data_draw_korea.csv사용
data = pd.read_csv('data/data_draw_korea.csv')
- iloc[] : column index, row index 줌
# iloc[]사용
data.iloc[0:3,0:3]

- iloc 또한 2개 간격으로 출력 가능~!!
data.iloc[0:20:2,0:3]

- unique() : 중복제거 : 광역시도 중복제거하기
# 광역시도 이름 확인(중복된 이름 빼고)
print(data['광역시도'].unique())

- unique() : 중복제거 : 행정구역 중복제거하기
print(data['행정구역'].unique())

- sample(원하는 갯수) : 원하는 갯수만큼 랜덤으로 가져오는 함수
data.sample(n=10)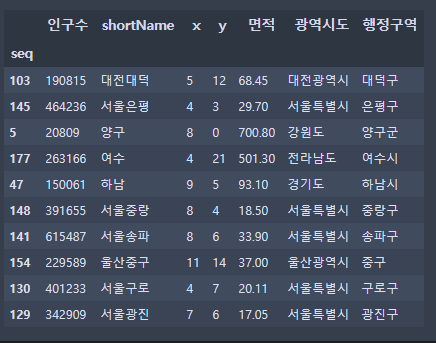
- 그룹화 함수 - values_count()
# 광역시도 이름별로 counting (그룹화해서 갯수 세주는 함수)
data['광역시도'].value_counts()

2. boolean indexing - 조건식을 만족하는 행을 선택
- data['광역시도] == '서울특별시' 와 같이 입력하면 행별로 True / False 형태로 출력된다.
data['광역시도'] == '서울특별시'
- data['광역시도] == '서울특별시' 를 loc에 넣어 광역시도가 서울특별시인 행만 출력
data.loc[data['광역시도']=='서울특별시',:]

- 원래 loc[ 행 , 열 ] 형태로 넣어야 하지만 boolean indexing 으로 할 경우 ,: (열 입력할 공간) 를 생략 가능
data.loc[data['광역시도']=='서울특별시']

- 조건을 변수에 담아 사용
# 부산광역시의 행정구역, 인구수 컬럼을 가져오기
busan = data['광역시도']=='부산광역시'
data.loc[busan,['행정구역','인구수']]

- 인구수 column에 대한 평균값 구하기
# 인구수 평균
pop_mean_value = data['인구수'].mean()
pop_mean_value

- 면적 column에 대한 평균값 구하기
# 면적에 대한 평균값
area_mean_value = data['면적'].mean()
area_mean_value

- 인구수가 평균보다 낮은 행정구역 가져오기
data.loc[data['인구수'] < pop_mean_value]

- 인구수가 평균보다 높은 행정구역 가져오기
data.loc[data['인구수'] > pop_mean_value]

- 인구수가 평균보다 높고, 면적도 평균보다 높은 지역 구하기
data.loc[(data['인구수'] > pop_mean_value) & (data['면적'] > area_mean_value)]
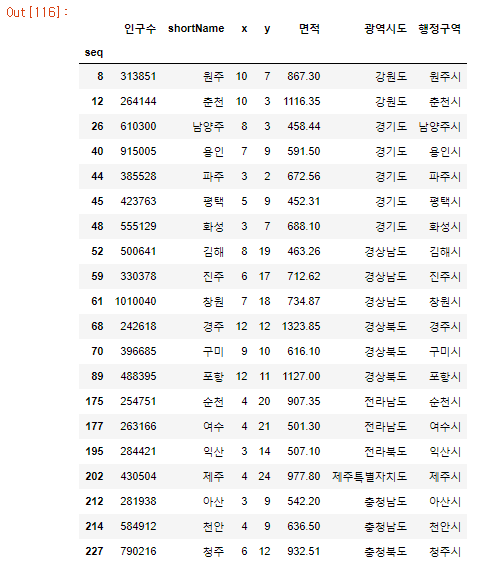
- 경기도에서 인구수가 평균보다 높은 행정구역 구하기
data.loc[(data['광역시도'] == '경기도') & (data['인구수'] > pop_mean_value),'행정구역']

- 강원도에서 가장 높은 인구수는?
data.loc[(data['광역시도'] == '강원도'),'인구수'].max() #결과 : 313851
- 람다함수를 사용해 지역별 가장 높은 인구수 구하기
# 람다함수
people_count = lambda area: data.loc[(data['광역시도'] == area),'인구수'].max()
people_count('강원도') #결과 : 313851
- 함수를 사용해 지역별 최대 인구수 구하기
# 힘수
def people_count(area):
return data.loc[(data['광역시도'] == area),'인구수'].max()
people_count('강원도') #결과 : 313851
- 지역별 최대 인구수를 가진 지역 정보 출력
data.loc[data['인구수'] == people_count('강원도')]

- 지역별 최대 인구수를 가진 지역 정보 출력 - 광역시도, 행정구역, 인구수 column만 출력!!
get_pop_max = lambda area : data.loc[data['인구수'] == people_count(area),['광역시도','행정구역','인구수']]
get_pop_max('부산광역시')

- 광역시도 이름을 중복제거했을때 type은 배열류 이다.
type(data['광역시도'].unique()) #numpy.ndarray는 동일한 타입만 넣을 수 있다.
#결과 : numpy.ndarray
- 모든 광역시도의 최대인구수와, 그 type출력(DataFrame)
for sido in data['광역시도'].unique():
print(get_pop_max(sido),type(get_pop_max(sido)))

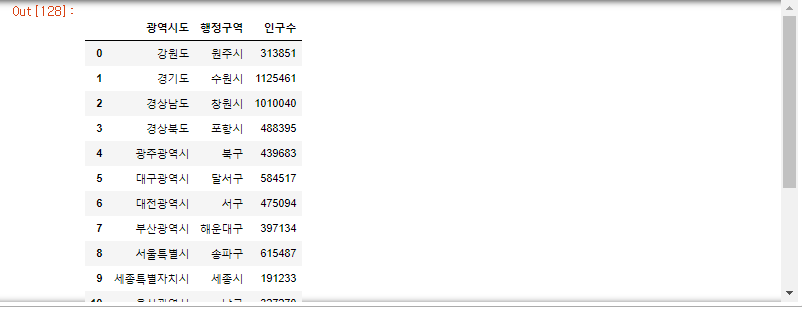
- DataFrame형태로 이쁘게 출력하기 위해 DataFrame객체 생성 후 append한다.
# 새로운 DateFrame 객체 생성하기
max_pop_df = pd.DataFrame(columns=['광역시도','행정구역','인구수'])
for sido in data['광역시도'].unique():
#print(get_pop_max(sido))
max_pop_df = max_pop_df.append(get_pop_max(sido)) #리스트와 달리 append하고 끝나는게 아니라 대입 시켜줘야함
max_pop_df

- reset_index(True / False) : True로 지정할 경우 기존 인덱스 값 초기화 !!
# reset_index(drop=False) - 인덱스 조정
# 인덱스를 변경하면서 기존 인데그 값을 컴럼으로 변경
# drop = True로 설정하면 기존 인덱스값이 포함된 index컬럼을 drop하겠다.
max_pop_df = max_pop_df.reset_index(drop=True)
max_pop_df
- index를 확인해본 결과
max_pop_df.index
# 결과 : RangeIndex(start=0, stop=17, step=1)
- index가 0이 아닌 1부터 출력하기 위해선? numpy를 import하여 사용
#인덱스를 1부터 시작하는 방법
import numpy as np
#index값을 변경
max_pop_df.index = np.arange(1,len(max_pop_df)+1)
# index값을 조회
print(max_pop_df.index)
max_pop_df

- sort_values()를 통해 인구수를 기준으로 내림차순
# 값을 원하는 조건으로 정렬
# shift + tab : 함수 help(인자, 내용에 대한 설명 볼 수 있음)
max_pop_df.sort_values(by='인구수', ascending=False).reset_index(drop=True)

- 지역별 면적에 대해서 가장 넓은 지역의 광역시도, 행정구역, 면적 이쁘게 출력하기
max_area = lambda area : data.loc[(data['광역시도'] == area),'인구수'].max()
#max_area('서울특별시')
max_area_func = lambda area : data.loc[data['인구수'] == max_area(area),['광역시도','행정구역','면적']]
max_area_df = pd.DataFrame(columns=['광역시도','행정구역','면적'])
for sido in data['광역시도'].unique():
max_area_df = max_area_df.append(max_area_func(sido))
max_area_df

3. Group by 기능 사용하기
- Series 객체의 groupby()
- DataFrame 객체의 groupby()
- 그룹함수를 통해 광역시도 별 갯수 구하기
data['광역시도'].value_counts()

- group by () 사용해 광역시도별 인구수 합계 구하기
# 광역시도별 인구수 합계
# ~별 에 해당하는 컬럼은 groupby() 함수의 파라미터로 전달한다.
# SeriesGroupBy 객체
data['인구수'].groupby(data['광역시도']).sum()

- 광역시도별 인구수 합계를 내림차순한 결과
data['인구수'].groupby(data['광역시도']).sum().sort_values(ascending=False)

- 광역시도별 면적 합계 내림차순
# 광역시도별 면적 합계
data['면적'].groupby(data['광역시도']).sum().sort_values(ascending=False)

- DataFrame 객체의 groupby
data.groupby('광역시도')
# 결과 : <pandas.core.groupby.groupby.DataFrameGroupBy object at 0x000001E9AD527470>** data['면적'].groupby(data['광역시도']) - 면적만 가져왔기 때문에 광역시도 컬럼을 들고와야함 (data['광역시도'])
** data.groupby('광역시도') - data에 7개의 컬럼이 다 들어있어 --> 컬럼명만 줘도 됨 ('광역시도')
- 광역시도별 인구수의 합계
# DataFrame 객체의 groupby
data.groupby('광역시도')['인구수'].sum()

- 광역시도별 면적의 합계
# 광역시도별 면적의 합계
data.groupby('광역시도')['면적'].sum()

- 광역시도별, 행정구역별 인구수
data.groupby(['광역시도','행정구역'])['인구수'].sum()

- 광역시도별, 행정구역별 인구수 type은 Series이다. - 인구수 column만 출력되기 때문에
grouping_data = data.groupby(['광역시도','행정구역'])['인구수'].sum()
type(grouping_data) #pandas.core.series.Series
- DataFrame을 Excel로 저장하기!!
# DataFrame을 Excel로 저장하기
grouping_data.to_excel('data/광역시도행정구역별인구수.xlsx',sheet_name='인구수')

4. matplot 사용하기
- jupyter notebook에 플롯이 그려지게 하기위한 설정
- 이 설정을 하면 notebook에서 show() 함수를 호출하지 않아도 plot이 출력된다.
%matplotlib inline
- 버전을 확인해보니 pandas버전이 낮아 버전을 높혀주었다.
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import seaborn as sns
print('matplotlib 버전 : ',matplotlib.__version__) #matplotlib 버전 : 2.2.3
print('seaborn 버전 : ',sns.__version__) #seaborn 버전 : 0.9.0
print('pandas 버전 : ',pd.__version__) #pandas 버전 : 0.23
- Pandas Version을 높히기 위해 원래 Version을 uninstall하고 다시 다운

- Matplot에 한글폰트 설정하기
- 먼저 windows/Fonts에서 맑은고딕 폰트 이름확인
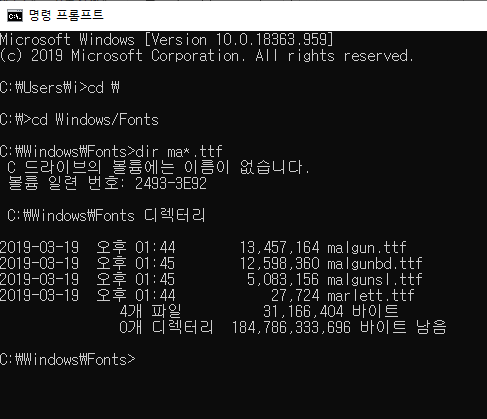
- cmd창에서 확인한 경로로 path저장후 이름 가져와 matplot에 설정
# Matplotlib에 맑은고딕 한글폰트 설정하기
font_path = 'C:/Windows/Fonts/malgun.ttf'
# font property 가져오기
font_prop = fm.FontProperties(fname=font_path).get_name()
# Matplotlib의 rc(run command) 명령을 사용해서 한글폰트 설정
matplotlib.rc('font',family=font_prop)
- 행정구역별 인구수, 면적 내림차순 형태로 출력하기
# figure와 plot을 생성
figure, (axes1, axes2) = plt.subplots(nrows=2, ncols=1)
# figure size 조정
figure.set_size_inches(18, 12)
print(figure)
print(axes1, axes2)
sns.barplot(data=seoul_df.sort_values(by='인구수',ascending=False), x='행정구역', y='인구수', ax=axes1)
sns.barplot(data=seoul_df.sort_values(by='면적',ascending=False), x='행정구역', y='면적', ax=axes2)

- 함수로 만들어 사용하기!!
def all_world_df(sido):
data_df = data.loc[data['광역시도'] == sido]
# figure와 plot을 생성
figure, (axes1, axes2) = plt.subplots(nrows=2, ncols=1)
# figure size 조정
figure.set_size_inches(18, 12)
sns.barplot(data=data_df.sort_values(by='인구수',ascending=False), x='행정구역', y='인구수',\
ax=axes1)
sns.barplot(data=data_df.sort_values(by='인구수',ascending=False), x='행정구역', y='인구수',\
ax=axes2)
all_world_df('서울특별시')

5. Maria DB 설치
1) mariadb 를 다운받는다.
Download MariaDB Server - MariaDB.org
REST API MariaDB Repositories Release Schedule Reporting Bugs […]
mariadb.org

2) 다운로드를 완료한 뒤 Command Prompt파일을 연다.

3) command창에 다음 명령어를 실행한다.
#MySQL Database 생성
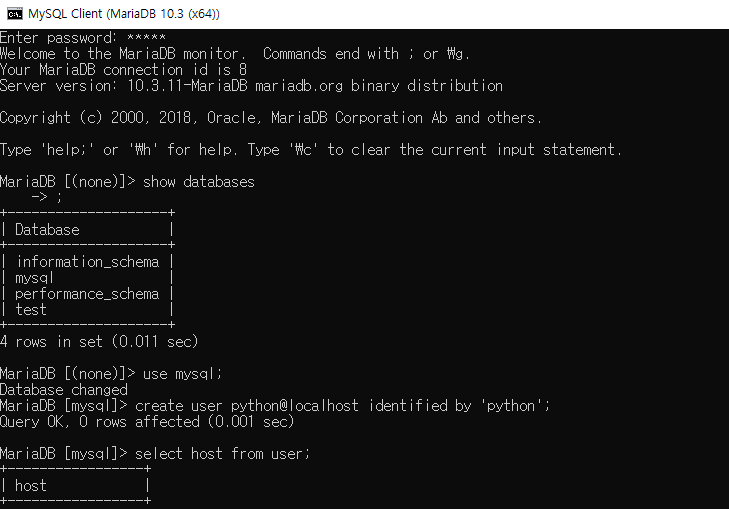
mysql -u root –p
show databases;
use mysql;
create user python@localhost identified by 'python';
grant all on *.* to python@localhost;
flush privileges;
exit;
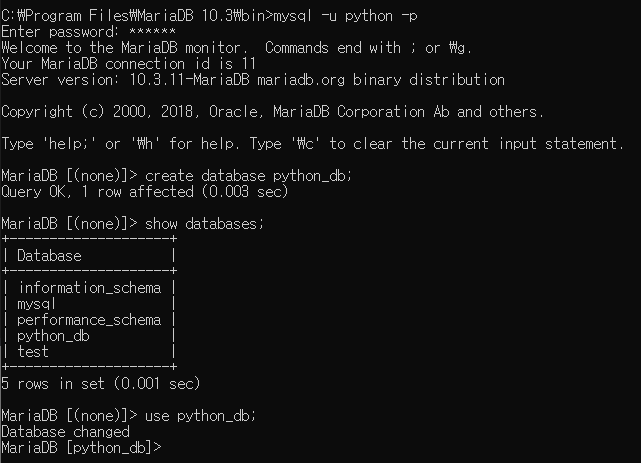
mysql -u python -p
create database python_db;
show databases;
use python_db;
3-1)
3-2)

3-3)
6. MariaDB연동
- pymysql 과 sqlalchemy 사용
- pymysql : python프로그램과 DB연결해주는 역할
- sqlalchemy : object(DataFrame)를 DB의 Table로 매핑해주는 역할
- pymysql 과 sqlalchemy가 설치되어있는지 확인

- DB연결 및 테이블 생성(위에서 만든 max_pop_df 라는 DataFrame을 통째로 maxpop이름의 테이블로 만듬)
# max_pop_df를 max_pop_table로 저장
import pymysql
pymysql.install_as_MySQLdb()
from sqlalchemy import create_engine
engine = create_engine('mysql+mysqldb://python:'+'python'+'@localhost/python_db',encoding='utf-8')
conn = engine.connect()
max_pop_df.to_sql(name='maxpop',con=engine,if_exists='replace',index=False)

7. 기타
- jupyter notebook 테마변경시 참조
https://chancoding.tistory.com/48
Jupyter Notebook Theme 상세 설정 자세하게 알아보자
> 주피터 노트북 테마 자세하게 알아보기 이전에 주피터 노트북 테마 스킨 설치 및 설정하는 방법에 대해서는 알아보았습니다. 하지만 좀 더 상사하게 설정하는 방법을 알아보도록 하겠습니다.
chancoding.tistory.com
https://chancoding.tistory.com/47
주피터 노트북 테마 스킨 - 전체 사진으로 비교 jupyter theme 비교하기
> 쥬피터 노트북 테마 전체 비교하기 코딩 쪽으로 진로를 정하면서 코딩을 많이 하게 되었습니다. 그러다 보니 하루 종일 컴퓨터에서 작업해야 하니 눈이 아프더라고요. 그래서 스킨을 조금 더 �
chancoding.tistory.com
- python에서 유명한 코드 경진대회? 사이트
https://www.kaggle.com/c/titanic/data
Titanic: Machine Learning from Disaster
Start here! Predict survival on the Titanic and get familiar with ML basics
www.kaggle.com
'Python > Python 웹 크롤링' 카테고리의 다른 글
| Selenium (0) | 2020.07.29 |
|---|---|
| 파이썬 OpenAPI_07월 24일 (0) | 2020.07.24 |
| 파이썬 OpenAPI_07월 22일 (0) | 2020.07.22 |
| 파이썬 OpenAPI_07월 21일 (0) | 2020.07.21 |
| 파이썬 OpenAPI_07월 20일 (0) | 2020.07.20 |