
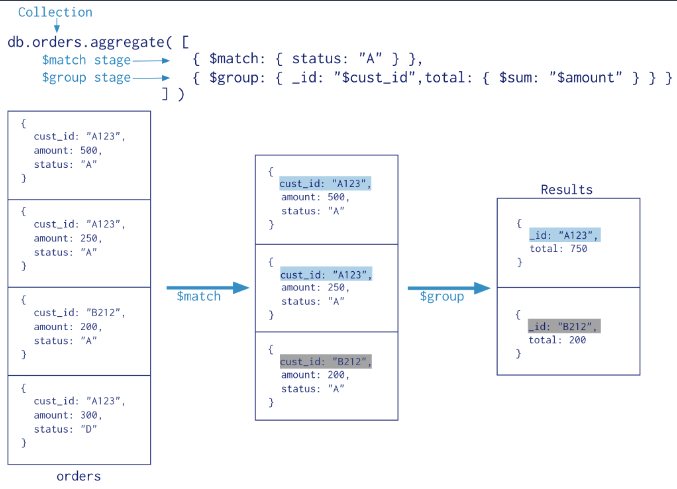
1. MongoDB Aggregation Pipeline
- Mongo DB의 Aggregation Framework는 데이터 처리 파이프라인의 개념을 모델로 합니다.
- 문서는 여러 단계의 파이프라인을 거쳐 변화하고 하나의 문서의 형태로 집계할 수 있습니다.
- 파이프라인(pipeline) 이란, 이전 단계의 연산결과를 다음 단계연산에 이용하는 것을 의미합니다.
- $match :
- 조건에 만족하는 Document만 Filtering
- 입력형식 : { $match: { } }
- $group :
- Document에 대한 Grouping 연산을 수행
- Group에 대한 id를 지정해야하고, 특정 필드에 대한 집계 연산이 가능
- $group은 연산된 Document에 대한 정렬을 지원하지 않음
- 입력형식 - { $group: { _id: <expression>, <field1>: { <accumulator1> : <expression1> }, ... } }
- $unwind
- Document내의 배열 필드를 기반으로 각각의 Document로 분리
- $unwind (aggregation)

- date format 참고 URL
https://docs.mongodb.com/manual/reference/operator/aggregation/dateToString/
$dateToString (aggregation) — MongoDB Manual
Optional. The date format specification. can be any string literal, containing 0 or more format specifiers. For a list of specifiers available, see Format Specifiers. If unspecified, $dateToString uses "%Y-%m-%dT%H:%M:%S.%LZ" as the default format. Changed
docs.mongodb.com
- aggregate 사용 연습
use python_db
db.createCollection('articles')
show collections
db.articles.insertMany([
{ "_id" : ObjectId("512bc95fe835e68f199c8686"), "author" : "john", "score" : 80, "views" : 100 },
{ "_id" : ObjectId("512bc962e835e68f199c8687"), "author" : "john", "score" : 85, "views" : 521 },
{ "_id" : ObjectId("55f5a192d4bede9ac365b257"), "author" : "ahn", "score" : 60, "views" : 1000 },
{ "_id" : ObjectId("55f5a192d4bede9ac365b258"), "author" : "li", "score" : 55, "views" : 5000 },
{ "_id" : ObjectId("55f5a1d3d4bede9ac365b259"), "author" : "annT", "score" : 60, "views" : 50 },
{ "_id" : ObjectId("55f5a1d3d4bede9ac365b25a"), "author" : "li", "score" : 94, "views" : 999 },
{ "_id" : ObjectId("55f5a1d3d4bede9ac365b25b"), "author" : "ty", "score" : 95, "views" : 1000 }
])
db.articles.find()
db.articles.aggregate([
{$match:{author:'john'}}
])
//score >= 80
db.articles.aggregate([
{$match:{score:{$gte:80}}}
])
//author = 'li' and score >= 60
db.articles.aggregate([
{$match:{
author:'li',
score:{$gte:60}
}}
])
//select author, sum(score) as total from srticles group by author
//having total > 100
db.articles.aggregate([
{$group:{
_id:'$author',
total:{$sum:'$score'}
}
},
{
$match:{
total:{$gt:100}
}
}
])
db.createCollection('orders')
show collections
db.orders.deleteMany({})
db.orders.insertMany([
{
cust_id: "abc123",
ord_date: ISODate("2012-01-02T17:04:11.102Z"),
status: 'A',
price: 100,
items: [ { sku: "xxx", qty: 25, price: 1 },
{ sku: "yyy", qty: 25, price: 1 } ]
},
{
cust_id: "abc123",
ord_date: ISODate("2012-01-02T17:04:11.102Z"),
status: 'A',
price: 500,
items: [ { sku: "xxx", qty: 25, price: 1 },
{ sku: "yyy", qty: 25, price: 1 } ]
},
{
cust_id: "abc123",
ord_date: ISODate("2012-01-02T17:04:11.102Z"),
status: 'B',
price: 130,
items: [ { sku: "jkl", qty: 35, price: 2 },
{ sku: "abv", qty: 35, price: 1 } ]
},
{
cust_id: "abc123",
ord_date: ISODate("2012-01-02T17:04:11.102Z"),
status: 'B',
price: 230,
items: [ { sku: "jkl", qty: 25, price: 2 },
{ sku: "abv", qty: 25, price: 1 } ]
},
{
cust_id: "abc123",
ord_date: ISODate("2012-01-02T17:04:11.102Z"),
status: 'A',
price: 130,
items: [ { sku: "xxx", qty: 15, price: 1 },
{ sku: "yyy", qty: 15, price: 1 } ]
},
{
cust_id: "abc456",
ord_date: ISODate("2012-02-02T17:04:11.102Z"),
status: 'C',
price: 70,
items: [ { sku: "jkl", qty: 45, price: 2 },
{ sku: "abv", qty: 45, price: 3 } ]
},
{
cust_id: "abc456",
ord_date: ISODate("2012-02-02T17:04:11.102Z"),
status: 'A',
price: 150,
items: [ { sku: "xxx", qty: 35, price: 4 },
{ sku: "yyy", qty: 35, price: 5 } ]
},
{
cust_id: "abc456",
ord_date: ISODate("2012-02-02T17:04:11.102Z"),
status: 'B',
price: 20,
items: [ { sku: "jkl", qty: 45, price: 2 },
{ sku: "abv", qty: 45, price: 1 } ]
},
{
cust_id: "abc456",
ord_date: ISODate("2012-02-02T17:04:11.102Z"),
status: 'B',
price: 120,
items: [ { sku: "jkl", qty: 45, price: 2 },
{ sku: "abv", qty: 45, price: 1 } ]
},
{
cust_id: "abc780",
ord_date: ISODate("2012-02-02T17:04:11.102Z"),
status: 'B',
price: 260,
items: [ { sku: "jkl", qty: 50, price: 2 },
{ sku: "abv", qty: 35, price: 1 } ]
}
])
db.orders.find()
//select count(*) as count from orders
db.orders.aggregate([
{
$group:{
_id:null,
count:{$sum:1}
}
}
])
//select sum(price) as total from orders
db.orders.aggregate([
{
$group:{
_id:null,
total:{$sum:'$price'}
}
}
])
//select cust_id, sum(price) as total from orders group by cust_id
db.orders.aggregate([
{
$group:{
_id:'$cust_id',
total:{$sum:'$price'}
}
}
])
//select cust_id, sum(price) as total from orders group by cust_id order by total
db.orders.aggregate([
{
$group:{
_id:'$cust_id',
total:{$sum:'$price'}
}
},
{
$sort:{total:1}
}
])
//select cust_id, ord_date, sum(price) as total
//from orders group by cust_id, ord_date
db.orders.aggregate([
{
$group:{
_id:{
cust_id:'$cust_id',
ord_date:{$dateToString: { format: "%Y-%m-%d", date: "$ord_date" }}
},
total:{$sum:'$price'}
}
}
])
//select cust_id, count(*) from orders group by cust_id having count(*) > 1
db.orders.aggregate([
{$group:{_id:'$cust_id',
count:{$sum:1}}},
{$match:{count:{$gt:1}}}
])
//select status, count(*) from orders group by status havint count(*) > 1
db.orders.aggregate([
{$group:{_id:'$status',
count:{$sum:1}}},
{$match:{count:{$gt:1}}}
])
//select status, sum(price) as total from orders group by status
db.orders.aggregate([
{$group:{_id:'$status',
total:{$sum:'$price'}}}
])
//select cust_id, ord_date, sum(price) as total
//from orders group by cust_id, ord_date
//having total > 250
db.orders.aggregate([
{
$group:{
_id:{
cust_id:'$cust_id',
ord_date:{$dateToString: { format: "%Y-%m-%d", date: "$ord_date" }}
},
total:{$sum:'$price'}
}
},
{$match:{total:{$gt:250}}}
])
//select cust_id, sum(price) as total from orders where status='A' group by cust_id
db.orders.aggregate([
{$match:{status:'B'}},
{$group:{_id:'$cust_id',total:{$sum:'$price'}}}
])
//select cust_id, ord_date, sum(price) as total from orders where status='B'
//group by cust_id, ord_date having total > 250
db.orders.aggregate([
{$match:{status:'B'}},
{$group:{_id:
{cust_id:'$cust_id',
ord_date:{$dateToString: { format: "%Y-%m-%d", date: "$ord_date" }}},
total:{$sum:'$price'}}},
{$match:{total:{$gt:250}}}
])
/*
select cust_id, sum(li.qty) as qty
from orders o, order_lineitem li
where o.id = li.order_id
group by cust_id
*/
db.orders.aggregate([
{$unwind:'$items'},
{$group:{_id:'$cust_id',qty:{$sum:'$items.qty'}}}
])
db.orders.find()
/*
select count(*)
from
(select cust_id, ord_date
from orders
group by cust_id, ord_date) as d
*/
db.orders.aggregate([
{$group:{_id:{cust_id:'$cust_id',ord_date:{$dateToString: { format: "%Y-%m-%d", date: "$ord_date" }}}}},
{$group:{_id:null,count:{$sum:1}}}
])
//items collection 생성
db.createCollection('items')
show collections
db.items.insertMany([
{ "_id" : 1, "item" : "abc", "price" : 10, "quantity" : 2, "date" : ISODate("2014-03-01T08:00:00Z") },
{ "_id" : 2, "item" : "jkl", "price" : 20, "quantity" : 1, "date" : ISODate("2014-03-01T09:00:00Z") },
{ "_id" : 3, "item" : "xyz", "price" : 5, "quantity" : 10, "date" : ISODate("2014-03-15T09:00:00Z") },
{ "_id" : 4, "item" : "xyz", "price" : 5, "quantity" : 20, "date" : ISODate("2014-04-04T11:21:39.736Z") },
{ "_id" : 5, "item" : "abc", "price" : 10, "quantity" : 10, "date" : ISODate("2014-04-04T21:23:13.331Z") }
])
//
db.items.aggregate([
{$group:{_id:{year:{$year:'$date'},month:{$month:'$date'},day:{$dayOfMonth:'$date'}},
totalPrice:{$sum:{$multiply:['$price','$quantity']}},
avgQuantity:{$avg:'$quantity'},
count:{$sum:1}}}
])
db.createCollection('inventory')
db.inventory.insertOne({ "_id" : 1, "item" : "ABC1", sizes: [ "S", "M", "L"] })
db.inventory.find()
db.inventory.aggregate([
{$unwind:'$sizes'}
])2. Pymongo를 사용해서 MongoDB 제어하기
- pymongo라이브러리 import
- MongoDB 접속
- Database, Collection 생성
- Collection의 document를 CRUD하기
- pymongo 연결,디비생성, 컬렉션생성
import pymongo
# connection 생성
conn = pymongo.MongoClient(host='localhost', port=27017)
print(conn)
# database 생성
db = conn.pymongo_db
print(db)
print(db.name)
# collection 생성
col = db.pymongo_col
print(col)
print(col.name)

insert_one(), insert_many() 함수
- insert_one() 사용해 하나의 데이터 넣기
post = {'author':'길동','text':'첫번째 글','tags':['mongodb','python','pymongo']}
result = col.insert_one(post)
print(result)
print(result.inserted_id)

- 데이터 조회 명령어 사용 - 객체 주소값 출력
col.find()

- 값 확인 위해 for문 돌리면 출력해야함
for post in col.find():
print(type(post))
print(post)

- 전체 데이터(document)갯수를 알아오는 함수 : count_document({})
- 하나의 document만 들어갔기 때문에 1이 출력됨
# document 갯수 알아내기
col.count_documents({}) #결과 : 1
- 변수로 만들어 저장할 데이터를 정의해준 후 insert하기
posts = [
{'author':'둘리','age':10},
{'author':'바다','age':20},
{'author':'연못','age':30}
]
col.insert_many(posts)

- 위에 insert를 여러번 실행했더니 여러번 데이터가 들어갔다.
print(col.count_documents({}))
for post in col.find({}):
print(post)

- 특정 field만 조회
for post in col.find({},{'author':1,'age':1,'text':1,'_id':0}):
print(post)
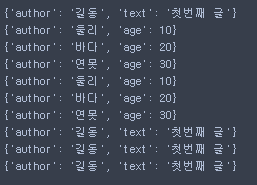
- sort를 사용해 오름차순 정렬
for post in col.find({},{'author':1,'age':1,'text':1,'_id':0}).sort('age',pymongo.ASCENDING):
print(post)

- sort를 사용해 내림차순 정렬
for post in col.find({},{'author':1,'age':1,'text':1,'_id':0}).sort('age',pymongo.DESCENDING):
print(post)

- employee collection 생성하기
# employees collection 생성하기
emp = db.employees
print(emp)

- 날짜 형태 바꿔서 insert하기 위해 datetime import
- strptime : 시, 분 또는 초를 나타내는 포맷 코드는 0 값을 보게 됩니다.
import datetime
datetime.datetime.strptime('2016-01-02','%Y-%m-%d')

- 날자 형태 바꿔서 insert 하기
emp_list = [
{"number":1001,"last_name":"Smith","first_name":"John","salary":62000,"department":"sales", 'hire_date':datetime.datetime.strptime('2016-01-02','%Y-%m-%d')},
{"number":1002,"last_name":"Anderson","first_name":"Jane","salary":57500,"department":"marketing", 'hire_date':datetime.datetime.strptime('2013-11-09','%Y-%m-%d')},
{"number":1003,"last_name":"Everest","first_name":"Brad","salary":71000,"department":"sales", 'hire_date':datetime.datetime.strptime('2017-02-03','%Y-%m-%d')},
{"number":1004,"last_name":"Horvath","first_name":"Jack","salary":42000,"department":"marketing", 'hire_date':datetime.datetime.strptime('2017-06-01','%Y-%m-%d')},
]
emp.insert_many(emp_list)

- insert 잘 됐나 데이터 조회하기
for employee in emp.find():
print(employee)

- like문 사용방법
# first_name like ''%a%''
filter = {'first_name':{'$regex':'a'}} #a가 포함되어있는
filter = {'first_name':{'$regex':'^J'}} #J로 시작되는
filter = {'last_name':{'$regex':'h$'}} #h로 끝나는
- select * from whrer number in (1001,1002) and hire_date >= '2016-01-02' and hire_date <= '2017-05-30' 문 pymongo로 작성해보기
from datetime import datetime
from_dt = datetime.strptime('2016-01-02','%Y-%m-%d')
to_dt = datetime.strptime('2017-05-30','%Y-%m-%d')
filter = {'hire_date':{'$gte':from_dt,'$lte':to_dt}}
filter = {'number':{'$in':[1001,1002]}}
for employee in emp.find(filter,{'_id':0}):
print(employee)

update_one(), update_many()
- update_one() 사용하기
emp.update_one({'number':1001},{'$set':{'department':'marketing'}})
# number = 1001, salary 62000 -> 63000
emp.update_one({'number':1001},{'$inc':{'salary':1000}})

- update_many() 사용하기(없었던 컬럼을 새로 만들어줬다. - status)
# status 컬럼 추가 (A값으로 넣어서)
emp.update_many({},{'$set':{'status':'A'}})

- update가 잘 적용되었는지 조회
for post in emp.find({},{'_id':0}):
print(post)

- update_many() 문 연습해보기
# update many()
# number in [1003,1004] - status = 'B'
emp.update_many({'number':{'$in':[1003,1004]}},{'$set':{'status':'B'}})
for post in emp.find({},{'_id':0}):
print(post)

- delete 사용하기
# delete many()
# status = 'B'
emp.delete_many({'status':'B'})
for post in emp.find({},{'_id':0}):
print(post)

Songs정보를 저장하고 읽기
- data/songs.json읽기
- MongoDB에 연결하기 - db, collection 생성
- insert_many()등록, find()조회
- songs.json파일
- json, pymongo import
- json파일을 읽어온다.
import json
import pymongo
# json file read
with open('data/songs.json','r',encoding='utf-8') as file:
content = file.read()
json_data = json.loads(content)
print(type(json_data))
json_data

- pymongo와 연결한 후 song_db라는 디비만든 후, song_col이라는 collection만든다.
conn = pymongo.MongoClient()
print(conn)
song_db = conn.song_db
print(song_db)
song_col = song_db.song_col
print(song_col)

- 불러온 songs.json data를 song_col 컬렉션에 insert한다.
song_col.insert_many(json_data)

- 전체 데이터(document)갯수를 알아오는 함수 : count_document({})
song_col.count_documents({})

- find함수를 통해 조회해본다.
- for문으로 돌려주며 출력해야함
for song in song_col.find({},{"_id":0,'가사':0}):
print(song)

- distinct기능 사용하기
# select distinct 장르 from songs
for genre in song_col.aggregate([{'$group':{'_id':'$장르'}}]):
print(genre)

- 조건이 있는 조회문 함수로 만들어 출력하기
def print_song(match, find):
for song_info in song_col.find(match,find):
print(song_info)# genre 가 댄스인 곡명, 가수, 앨범, 발매일
match = {'장르':'댄스'}
field = {'_id':0,'곡명':1,'가수':1,'앨범':1,'발매일':1}
print_song(match,field)

# 가수가 방탄소년단, 폴킴의 곡명, 가수, 앨범, 발매일
match = {'가수':{'$in':['방탄소년단','폴킴']}}
firlds = {'_id':0,'곡명':1,'가수':1,'앨범':1,'발매일':1}
print_song(match,field)

# 앨범 이름 중에서 OST가 포함된 노래의 곡명, 가수, 앨범, 발매일
match = {'앨범':{'$regex':'OST'}}
field = {'_id':0,'곡명':1,'가수':1,'앨범':1,'발매일':1}
print_song(match,field)

- 참고링크
https://docs.mongodb.com/manual/tutorial/aggregation-zip-code-data-set/
Aggregation with the Zip Code Data Set — MongoDB Manual
Aggregation with the Zip Code Data Set The examples in this document use the zipcodes collection. This collection is available at: media.mongodb.org/zips.json. Use mongoimport to load this data set into your mongod instance. Data Model Each document in the
docs.mongodb.com
'데이터베이스 > MongoDB' 카테고리의 다른 글
| Cine21_MongoDB저장_검색 (0) | 2020.08.04 |
|---|---|
| MongoDB aggregate 연습문제 (0) | 2020.07.31 |
| MongoDB 설치 (0) | 2020.07.29 |