
1. Melon 100 Chart 스크래핑
- 100곡 노래의 title, id 추출
- Song의 Detial 페이지로 100번 요청해서 상세정보 추출
- Pandas의 DataFrame에 저장
- DB에 Song Table로 저장
- 100곡 노래의 title, id 추출
* 멜론의 경우 user_agent가 필요!! - 멜론에서 그렇게 걸어놈 ㅇㅅㅇ - 로봇이 아님을 증명하기 위해 사용

import requests
from bs4 import BeautifulSoup
import re
url = 'https://www.melon.com/chart/index.htm'
request_header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
html = requests.get(url, headers=request_header).text
soup = BeautifulSoup(html,'html.parser')
# div#tb_list tr div.wrap_song_info a
# print(len(soup.select('#tb_list'))) #1개
# print(len(soup.select('#tb_list tr'))) #101개
# print(len(soup.select('#tb_list tr div.wrap_song_info'))) #200개
# print(len(soup.select('#tb_list tr div.wrap_song_info a'))) #418개
# print(len(soup.select("#tb_list tr div.wrap_song_info a[href*='playSong']"))) #100개
song_atag_list = soup.select("#tb_list tr div.wrap_song_info a[href*='playSong']")
song_list = []
for idx, song_atag in enumerate(song_atag_list,1):
song_dict = {}
song_title = song_atag.text
link = song_atag['href']
matched = re.search(r"(\d+)\)",link)
song_id = matched.group(1)
song_url = 'https://www.melon.com/song/detail.htm?songId={}'.format(song_id)
song_dict['song_url'] = song_url
song_dict['song_title'] = song_title
song_list.append(song_dict)
song_list

- 정규표현식 참고 사이트
RegExr: Learn, Build, & Test RegEx
RegExr is an online tool to learn, build, & test Regular Expressions (RegEx / RegExp).
regexr.com
http://www.nextree.co.kr/p4327/
정규표현식(Regular Expression)을 소개합니다.
날이 갈수록 개인정보 보호에 관련하여 보안정책을 점진적으로 강화하고 있습니다. 이에 따라 Web에서 회원가입 시 Password 설정을 복잡해진 보안정책에 맞추다 보니 복잡하게 조합해야만 정상적
www.nextree.co.kr
- https://regexr.com/ 사이트에서 코드를 text에 넣고 Expression에 정규표현식을 넣어가며 확인 가능
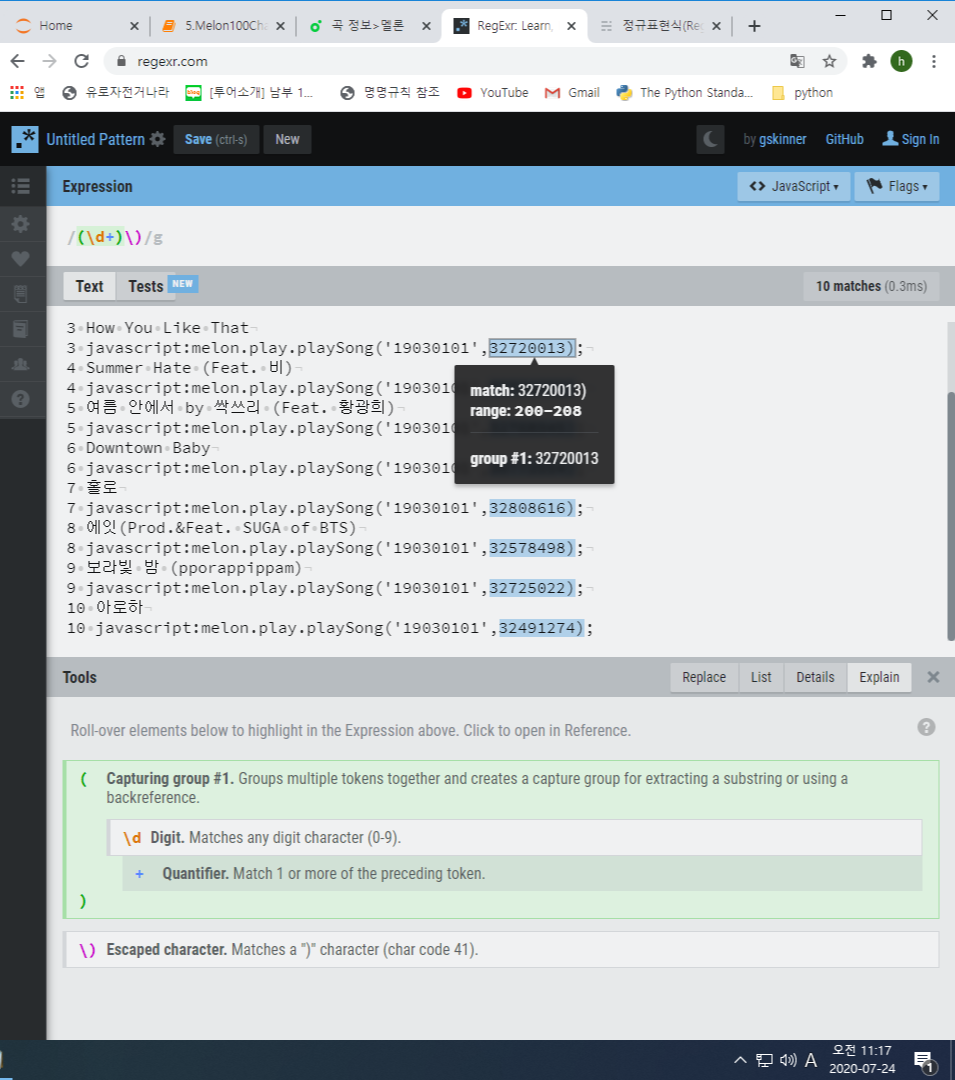
- 뽑아온 URL list를 다시 requests 보내서 곡명, 가수, 앨범, 발매일, 장르 등 받아오기
import requests
from bs4 import BeautifulSoup
import re
request_header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
song_lyric_lists = []
for song in song_list:
html = requests.get(song['url'], headers = request_header).text
soup = BeautifulSoup(html,'html.parser')
song_lyric_dict = {}
song_lyric_dict['곡명'] = song['title']
song_lyric_dict['가수'] = soup.select('a[href*=".goArtistDetail"] span')[0].text
song_lyric_dict['앨범'] = soup.select('div.meta dd')[0].text
song_lyric_dict['발매일'] = soup.select('div.meta dd')[1].text
song_lyric_dict['장르'] = soup.select('div.meta dd')[2].text
#song_lyric_dict['좋아요'] = soup.select('span#d_like_count')[0].text
lyric = soup.select('div#d_video_summary')[0].text
regex = re.compile(r'[\n\r\t]')
song_lyric_dict['가사'] = regex.sub('', lyric.strip())
song_lyric_lists.append(song_lyric_dict)
#print(song_lyric_dict)
print(len(song_lyric_lists),song_lyric_lists)

- DataFrame을 생성해 표 형태로 저장
# song_lylic_lists를 DataFrame으로 저장
# DB에 song라는 테이블로 저장
import pandas as pd
song_df = pd.DataFrame(columns=['곡명','가수','앨범','발매일','장르','가사'])
for song_info in song_lyric_lists:
series_obj = pd.Series(song_info)
song_df = song_df.append(series_obj, ignore_index=True)
song_df.head()

- MariaDB를 통해 song_df(데이터프레임 형태로 저장된 정보)를 song이라는 이름의 테이블로 저장
import pymysql
pymysql.install_as_MySQLdb()
from sqlalchemy import create_engine
engine = create_engine('mysql+mysqldb://python:'+'python'+'@localhost/python_db',encoding='utf-8')
conn = engine.connect()
song_df.to_sql(name='song', con=engine,if_exists='replace',index=False)

- Json데이터 읽어서 테이블만들기
# songs.json 파일을 읽어서 DataFrame으로 저장
import json
import pandas as pd
# json file read
with open('data/songs.json','r',encoding='utf-8') as file:
contents = file.read()
json_data = json.loads(contents)
print(len(json_data), json_data)

# DataFrame 생성
data_df = pd.DataFrame(columns=['곡명','가수','앨범','발매일','장르','가사'])
data_df.head()
for data in json_data:
#print(type(data)) #dict
series_obj = pd.Series(data)
data_df = data_df.append(series_obj, ignore_index=True)
data_df.head()
# 가수 value_counts()
# 갯수가 가장 많은 가수의 정보 출력
data_df.loc[data_df['가수']=='방탄소년단',['곡명','장르','앨범']] 
# column name 재설정
data_df.columns = ['title','singer','album','release_date','genre','lyric']
data_df.head()
# index 재설정
import numpy as np
data_df = data_df.reset_index(drop=True)
# index를 1부터 시작하기
data_df.index = np.arange(1,len(data_df)+1)
data_df.head(2)

# 각 컬럼의 값의 길이 length check
data_df['title'].str.len().sort_values(ascending=False).head(1)
# 함수로 만들기
col_length = lambda col : data_df[col].str.len().sort_values(ascending=False).head(1)
# column이름 for문 돌려가며 각 컬럼의 길이 구하기
for col_name in data_df.columns:
print(col_name, col_length(col_name))

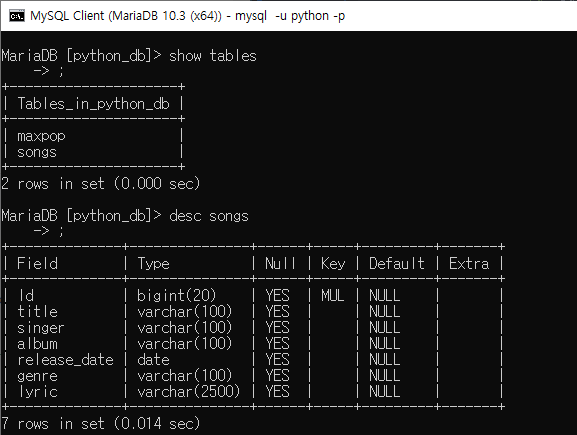
- DB 에 songs테이블로 저장
# DataFrame을 Songs Table로 생성하기
import pymysql
import sqlalchemy
pymysql.install_as_MySQLdb()
from sqlalchemy import create_engine
engine = create_engine('mysql+mysqldb://python:'+'python'+'@localhost/python_db',encoding='utf-8')
conn = engine.connect()
data_df.to_sql(name='songs', con=engine, if_exists='replace', index=True, index_label='Id',
dtype={
'Id':sqlalchemy.types.INTEGER(),
'title':sqlalchemy.types.VARCHAR(100),
'singer':sqlalchemy.types.VARCHAR(100),
'album':sqlalchemy.types.VARCHAR(100),
'release_date':sqlalchemy.DATE,
'genre':sqlalchemy.types.VARCHAR(100),
'lyric':sqlalchemy.types.VARCHAR(2500)
})
conn.close()
- Table을 DataFrame으로 저장
# Table을 DataFrame으로 저장
import pymysql
import sqlalchemy
pymysql.install_as_MySQLdb()
from sqlalchemy import create_engine
engine = create_engine('mysql+mysqldb://python:'+'python'+'@localhost/python_db',encoding='utf-8')
conn = engine.connect()
songs_df = pd.read_sql_table('songs',conn)
conn.close()
song_df.head()

- SQL Query 결과를 DataFrame으로 저장한다.
import pymysql
import sqlalchemy
pymysql.install_as_MySQLdb()
from sqlalchemy import create_engine
engine = create_engine('mysql+mysqldb://python:'+'python'+'@localhost/python_db',encoding='utf-8')
conn = engine.connect()
# select * from songs where album like '%OST %'
value = ' OST '
sql = '''select * from songs where album like %s;'''
query_df = pd.read_sql(sql,con=conn, params=('%'+ value + '%',))
conn.close()
query_df.head()
2. 국회의원 정보 스크래핑
- 국회의원이름, 국회의원id 추출
- 국회의원 상세 페이지에 300번 요청을 보내서 상세정보 추출
- Pandas DataFrame에 저장
- 시각화(막대그래프, 히스토그램, 파이차트)
- DB에 members테이블에 저장
1) 국회의원 사이트에 접속하면 다음과 같이 국회의원 정보가 나온다.
https://www.assembly.go.kr/assm/memact/congressman/memCond/memCond.do

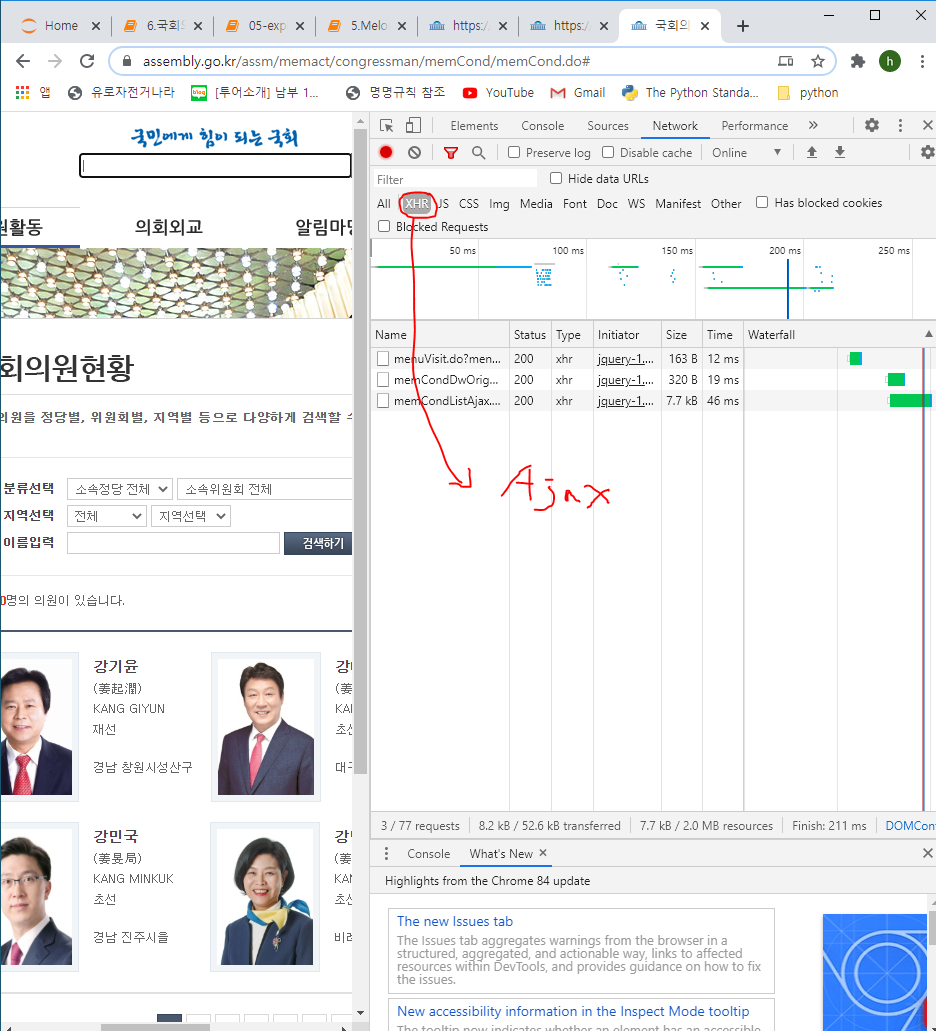
2) 소스코드 보기 통해 보면 국회의원 정보가 ajax를 통해 스크립트로 뿌려지는 형태로 되어있어 이름등을 바로 조회할 수 없는 것을 확인할 수 있다.
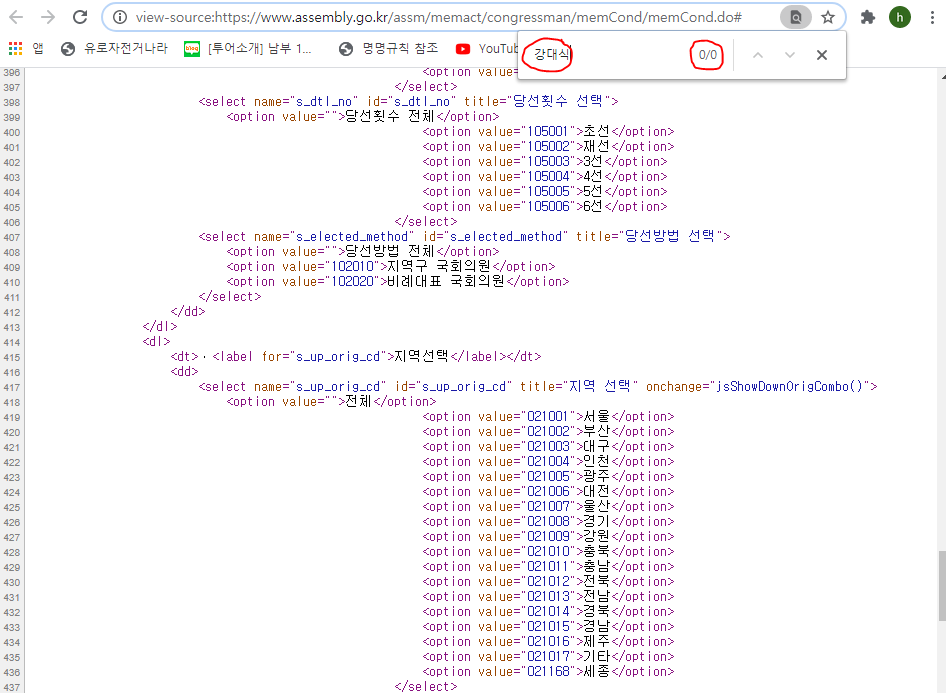
3) 스크립트로 뿌려지는 숨겨진 값을 확인하기 위해선 개발자툴 > Network > 새로도침 한 후, .do로 끝나는 것들을 더블클릭하여 하나씩 확인해본다.

4) memCondListAjax.do를 더블클릭한 결과 드디어 국회의원 정보를 볼 수있는 사이트로 이동하게 된다. 개발자 툴을 통해 소스를 보니 여기에선 국회의원 정보가 조회된다. 하지만 페이징 처리 때문에 6개밖에 보이지 않는다.
https://www.assembly.go.kr/assm/memact/congressman/memCond/memCondListAjax.do

5) 페이징 처리와 상광없이 300개를 전체 조회하기 위해선?
- 페이징 처리할때 날리는 값을 우선 확인한다.
- https://www.assembly.go.kr/assm/memact/congressman/memCond/memCond.do 사이트에서 개발자도구 > 네트워크 > Headers > 2페이지 버튼 클릭 > currentPage, movePageName, rowPerPage 값들이 생긴것을 확인할 수 있다.

- 2페이지를 눌렀을때, 3페이지를 눌렀을 때 정보를 확인해본 결과 아래와 같은 규칙으로 나오는 것을 확인했다.

- 이 규칙들을 적용해 기존 페이지 url(https://www.assembly.go.kr/assm/memact/congressman/memCond/memCondListAjax.do)에 "?currentPage=1&rowPerPage=300" 을 붙혀주면 한 페이지에서 국회의원 300명의 정보를 확인할 수 있다.
www.assembly.go.kr/assm/memact/congressman/memCond/memCondListAjax.do?currentPage=1&rowPerPage=300
6) www.assembly.go.kr/assm/memact/congressman/memCond/memCondListAjax.do?currentPage=1&rowPerPage=300에 존재하는 300명의 국회의원의 id값들을 가져온다.
- 정규표현식을 통해 id값만 뽑안내고, list에 담는다.
import requests
from bs4 import BeautifulSoup
import re
url = 'https://www.assembly.go.kr/assm/memact/congressman/memCond/memCondListAjax.do?currentPage=1&rowPerPage=300'
html = requests.get(url).text
soup = BeautifulSoup(html,'html.parser')
atag_list = soup.select(".memberna_list dl dt a")
# print(len(atag_list)) #300개
id_list = []
for idx, atag in enumerate(atag_list,1):
name = atag.text
link = atag['href']
matched = re.search(r"(\d+)",link)
member_id = matched.group(0)
id_list.append(member_id)
print(id_list)

7) 300명의 국회의원 상세페이지에서 이름, 생년원일, 정당.... 등등의 정보를 추출한다.

- 개발자 툴에서 소스를 보면 다음과 같다.

- 국회의원 정보, 이름, 이미지, 생년월일 추출 후 리스트에 저장
import requests
from bs4 import BeautifulSoup
import re
from urllib.parse import urljoin
print('------------작업시작-------------')
member_list = []
for idx, id in enumerate(id_list,1):
detail_url = f'https://www.assembly.go.kr/assm/memPop/memPopup.do?dept_cd={id}'
print(idx, id)
html = requests.get(detail_url).text
soup = BeautifulSoup(html,'html.parser')
# 국회의원 한명의 상세정보를 저장하는 dictionary
member_dict = {}
# dt tag만 추출
dt_list = []
for dt_tag in soup.select('.info_mna dl.pro_detail dt'):
dt_list.append(dt_tag.text)
# dd tag만 추출
dd_list = []
for dd_tag in soup.select('.info_mna dl.pro_detail dd'):
regex = re.compile(r'[\n\r\t]')
result = regex.sub('',dd_tag.text.strip()).replace(' ','')
dd_list.append(result)
member_dict = dict(zip(dt_list,dd_list))
for div_tag in soup.select('.info_mna .profile'):
#print(div_tag)
member_dict['이름'] = div_tag.select('h4')[0].text
img_url = div_tag.find('img').attrs['src']
member_dict['이미지'] = urljoin(detail_url,img_url)
member_dict['생년월일'] = div_tag.select_one('li:nth-of-type(4)').text
#print(birth_date)
member_list.append(member_dict)
#print(len(member_list))
print(member_list[298:])
print('------------작업종료-------------')re.compile - 내가 정규표현식을 새로 만듬
regex.sub(바꿀문자,대상) - regex.sub('',dd_tag.text.strip()).replace(' ','') --> 대상에 대해 내가 만든정규표현식으로 되어있는 것을 ''(문자열없음)으로 바꾼다. 그 뒤에도 제거되지 못한 공백을 제거하기 위해 replace를 써준다.

regex.sub('',dd_tag.text.strip()).replace('
...중간결과 생략

8) DataFrame으로 저장후 가공한 컬럼 추가
- 당선횟수를 중복제거하여 출력해보면 다음과 같이 출력
- 저렇게 긴 이름 말고, '재선'/'4선'.. 과같이 2글자만 나오도록 하는 컬럼을 따로 만들어보자!!
data_df['당선횟수'].unique()

- DataFrame에 저장한 과정
# [{},{},{}]
# {} -> Series(1개의 Row)
# [] -> DataFrame
import pandas as pd
data_df = pd.DataFrame(columns=['이름','이미지','생년원일','정당','선거구','소속위원회','당선횟수'\
,'사무실전화','홈페이지','이메일','보좌관','비서관','비서','취미, 특기'])
for member in member_list:
series_obj = pd.Series(member)
data_df = data_df.append(series_obj, ignore_index=True)
data_df.head()

- 당선횟수를 가공한 컬럼을 새로운 컬럼으로 추가하는 과정
- Series 형태를 String형태로 변환하여 slice를 하여 원하는 글자를 가져온다. ex) 재선(19대,21대) --> 재선
- 가공한 데이터로 6선인 사람의 데이터를 출력해보자
# 당선횟수2 컬럼을 생성
print(type(data_df['당선횟수'])) #<class 'pandas.core.series.Series'>
temp_str = data_df['당선횟수'].str
print(type(temp_str)) #<class 'pandas.core.strings.StringMethods'>
numberof_election = temp_str[:2]
data_df['당선횟수2'] = numberof_election
data_df.loc[:,['당선횟수','당선횟수2']].head()
data_df['당선횟수2'].value_counts()
data_df.loc[data_df['당선횟수2']=='6선',:]

- DateTimeIndex함수를 사용해 년/월/일 추출
# DateTimeindex 클래스를 이용해서 생년월일 컬럼에서 년/월/일 값을 추출
# year, month, day 3개의 컬럼을 추가
data_df['year'] = pd.DatetimeIndex(data_df['생년월일']).year
data_df['month'] = pd.DatetimeIndex(data_df['생년월일']).month
data_df['day'] = pd.DatetimeIndex(data_df['생년월일']).day
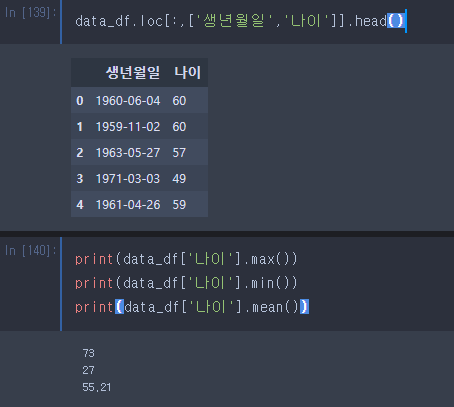
data_df.loc[:,['생년월일','year','month','day']].head()

- 추출결과를 통해 최대년도 / 최소년도 구하기

- 나이 계산 함수 구현
# 나이를 계산하는 함수 정의
from datetime import date
def calc_age(dtob):
my_today = date.today()
#print(my_today)
return my_today.year - dtob.year - ((my_today.month, my_today.day) < (dtob.month, dtob.day))
age_list = []
for idx, row in data_df.iterrows():
age = calc_age(date(row['year'], row['month'],row['day']))
age_list.append(age)
print(len(age_list),age_list[0:4]) #300 [60, 60, 57, 49]
data_df['나이'] = age_list
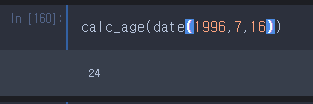
- 나이 열이 새로 생성되어 출력된 모습
- 경남창원시성산구 --> 경남 과 같이 지역이름만 나오도록 변경하여 선거구2 라는 열로 추가

- 선거구2 별 갯수 출력
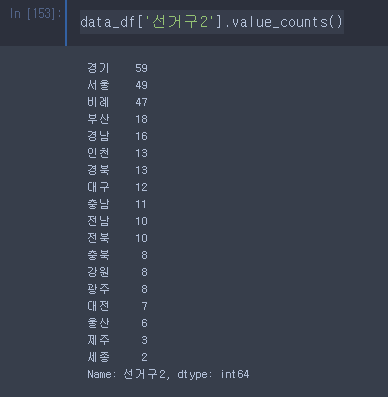
- 선거구2별 비율 출력

시각화(visualization)
- 이미지 출력 - Jupyter 에서 제고앟는 Image, display() 함수
- Matplotlib, Seaborn을 사용해서 그래프 그리기
- seaborn - countplot(막대그래프), distplot(히스토그램)
- matplotlib - histogram, pie chart
- 이미지 찍어보기
from IPython.display import Image, display
for image_url in data_df['이미지'].head(2):
print(type(image_url),image_url)
display(Image(url=image_url))

- 그래프 그리기 위해 폰트 설정
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import seaborn as sns
# setting seaborn default for plots
sns.set()
# Matplotlib에 맑은고딕 한글폰트 설정하기
font_path = 'C:/Windows/Fonts/malgun.ttf'
# font property 가져오기
font_prop = fm.FontProperties(fname=font_path).get_name()
# Matplotlib의 rc(run command) 명령을 사용해서 한글폰트 설정
matplotlib.rc('font',family=font_prop)
seaborn 막대그래프
- barplot - x축, y축을 모두 설정할 수 있음
- countplot - x축 이나 y축을 하나만 설정할 수 있음
- countplot사용해 정당별 갯수, 당선횟수별 갯수 표로 나타내기
# figure와 axes 생성
figure,(ax1,ax2) = plt.subplots(nrows=2,ncols=1)
figure.set_size_inches(18,12)
sns.countplot(data=data_df, x='정당', ax=ax1)
sns.countplot(data=data_df, y='당선횟수2', ax=ax2)

- countplot사용해 정당별 갯수, 당선횟수별 갯수 표로 나타내기, 큰 수부터 내림차순
# figure와 axes 생성
figure,(ax1,ax2) = plt.subplots(nrows=2,ncols=1)
figure.set_size_inches(18,12)
sns.countplot(data=data_df, x='정당', ax=ax1, order=data_df['정당'].value_counts().index)
sns.countplot(data=data_df, y='당선횟수2', ax=ax2, order=data_df['당선횟수2'].value_counts().index)
# sns.countplot(data=data_df, x='정당', ax=ax1)
# sns.countplot(data=data_df, y='당선횟수2', ax=ax2)
# print(data_df['정당'].value_counts().index) #Index(['더불어민주당', '미래통합당', '무소속', '정의당', '국민의당', '열린민주당', '기본소득당', '시대전환'], dtype='object')
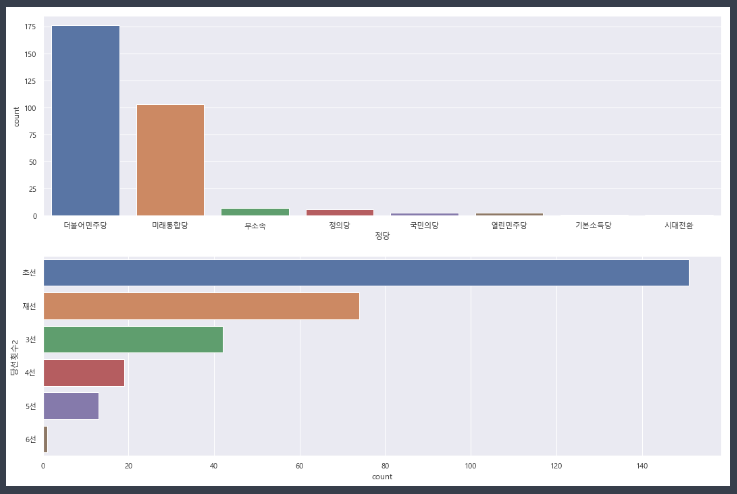
- countplot사용해 선거수별 갯수 표로 나타내기
# 선거구2 컬럼의 값을 countplot을 이용해서 plot을 그리기
# figure 에 axes 1개로 설정
# countplot에서 y축에 선거구2 컬럼을 설정한다.
figure, ax1 = plt.subplots(nrows=1, ncols=1)
figure.set_size_inches(18,12)
sns.countplot(data=data_df, y='선거구2', ax=ax1)

jupyter 에서 warning 메시지
- import warnings
- warning 메시지를 숨기고 싶으면 warnings.filterwarnings(action='ignore')
- warning 메시지를 다시 보고 싶으면 warnings.filterwarnings(action='default')
- 빨간색 처럼 나오는 것은 warning 메세지라고 한다. 이 warning 메세지를 보고싶지 않다면 다음과 같이 설정한다.
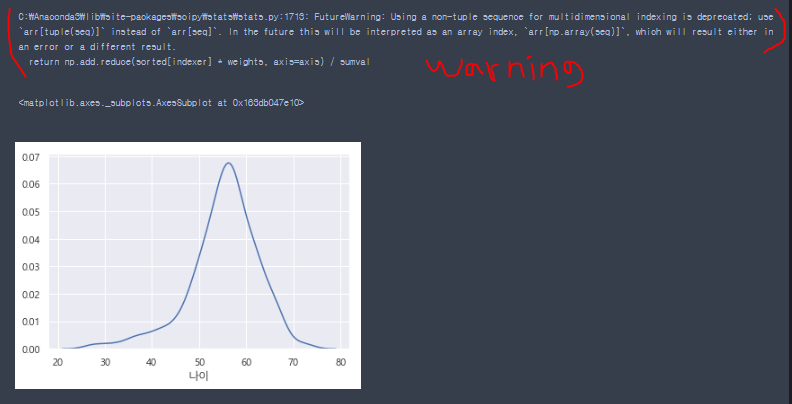
- warnwarnings.filterwarnings(action='ignore') 사용하여 경고 메세지 없애기
import warnings
warnings.filterwarnings(action='ignore')
- 경고메세지 없이 히스토그램 출력됨, distplot에서 hist=False로 설정하면 선만 나오는 히스토그램으로 출력
# seaborn에서 제공
# 나이 분포를 볼 수 있는 히스토그램을 출력
sns.distplot(data_df['나이'],hist=False)

- distplot에서 hist=True로 설정하면 선과 표가 함께 있는 히스토그램으로 출력
sns.distplot(data_df['나이'],hist=True)
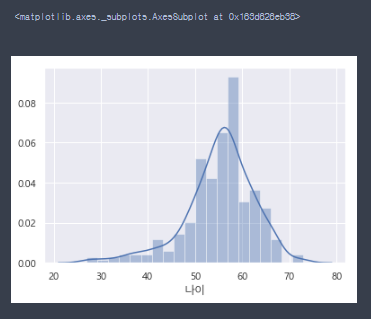
- 히스토그램에 30대, 70대가 있는것을 보고 30대, 70대의 정보가 궁금해져 찾아본다.
data_df.loc[(data_df['나이']<30) | (data_df['나이']>70),['이름','정당','나이']]
- warning에 대해 기본적으로 설정되어있는 default값으로 변경하면 다시 warning이 나오는 것을 확인할 수 있다.
warnings.filterwarnings(action='default')# 나이 분포를 볼 수 있는 히스토그램을 출력
sns.distplot(data_df['나이'],hist=False)
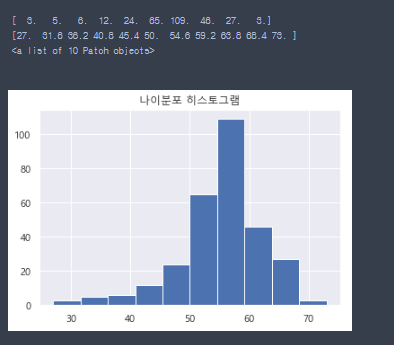
- matplotlib의 histogram그리기
plt.title('나이분포 히스토그램')
arrays, bins, patches = plt.hist(data_df['나이'])
print(arrays) # 구간별로 몇명이 있는지
print(bins) # 구간
print(patches)
plt.show() # 원래는 이거 써줘야 보이지만 안해줘도 보이는 이유는 위에서 %matplotlib inline 이 설정을 해줬기 때문
- 선거구2 컬럼의 값을 matplotlib의 pie plot을 사용해서 그려보기위해 퍼센디지 비율로 변경
# row count를 퍼센티지 비율로 나타내려면 value_counts(normalize=True)로 실행해야함
cdf = data_df['선거구2'].value_counts(normalize=True)
print(cdf)
print(cdf.index)

- 선거구2 컬럼의 값을 matplotlib의 pie plot을 사용해서 그려보기
# figure size조절
plt.figure(figsize=(20,12))
# pyplot의 pie() 함수 사용
# autopct = 퍼센디지 포멧지정
# startangle = 첫번째 pie의 시작각도 wlwjd
plt.pie(cdf,labels=cdf.index,autopct='%1.1f%%',startangle=140, shadow=True)
# pie plot을 그릴때 운의 형태를 유지할 수 있도록
plt.axis('equal')
plt.title('선거구 분포')

- DB에 저장하기
# '이름','이미지','생년월일', '나이','정당','선거구2','소속위원회','당선횟수2','사무실전화', '홈페이지', '이메일','보좌관','비서관','비서','취미, 특기'r
# 위와 같은 컬럼을 선택해서 새로운 DataFrame을 생성하고
# index 1부터
# table명 : members
table_df = data_df.loc[:,['이름','이미지','생년월일', '나이','정당','선거구2','소속위원회','당선횟수2'\
,'사무실전화', '홈페이지', '이메일','보좌관','비서관','비서','취미, 특기']]
table_df.columns = ['이름', '이미지', '생년월일', '나이', '정당', '선거구', '소속위원회', '당선횟수', \
'사무실전화', '홈페이지','이메일', '보좌관', '비서관', '비서', '취미특기']
table_df
import numpy as np
table_df = table_df.reset_index(drop=True)
table_df.index = np.arange(1,len(table_df)+1)
table_df.head(2)
# DataFrame을 mambers Table로 생성하기
import pymysql
import sqlalchemy
pymysql.install_as_MySQLdb()
from sqlalchemy import create_engine
engine = create_engine('mysql+mysqldb://python:'+'python'+'@localhost/python_db',encoding='utf-8')
conn = engine.connect()
table_df.to_sql(name='members', con=engine, if_exists='replace', index=True, index_label='id')
conn.close()
table_df

5. 기타
- 과제 7월 31일까지 과제 진행 완료!!
- 디비에서 쿼리문으로 조건줄 수 있는데 Pandas에서 처리하는 이유는?
: 디비는 굉장히 비싼 자원이기 때문에 Pandas에서 최대한 걸른 후 필요한 정보만 디비로 가공하여 저장을 하기 위해
- Pandas에 있는 명령어 압축 pdf 사이트
https://pandas.pydata.org/Pandas_Cheat_Sheet.pdf
- Ajax(Asynchrounous Javascript And Xml) : 비동기 중요!!
기존웹 : 응답이 올때까지 아무짓도 안해
비동기 :
응답이 올때까지 기다리는게 아니라 화면 조작할 수 있음, 데이터만 받으면 client에서 동적으로 가공,
서버로부터 XML, Json형태의 데이터만 받아서 동적으로 (dynamic) html tag를 생성한다.
비동기 통신을 담당하는 javascript객체 XHR(XmlHttpRequest)
- 시험 : 8월10일(ncs평가사이트)
1. 유형 : 필답(30문항)/수행/태도 평가
2. 필답 - 4지선다형
python programming(12), web scrapping/분석(8), sql(4)/nosql(2), css selector, library역할
3. 수행평가 - 코드3문제
4. 난이도
'Python > Python 웹 크롤링' 카테고리의 다른 글
| Python - cine21 데이터 크롤링 (0) | 2020.07.31 |
|---|---|
| Selenium (0) | 2020.07.29 |
| 파이썬 OpenAPI_07월 23일 (0) | 2020.07.23 |
| 파이썬 OpenAPI_07월 22일 (0) | 2020.07.22 |
| 파이썬 OpenAPI_07월 21일 (0) | 2020.07.21 |