
1. 씨네 21에 있는 배우 정보를 크롤링 해보자
1. 씨네21 홈페이지에 접속
http://www.cine21.com/rank/person
씨네21
대한민국 최고 영화전문매체
www.cine21.com
- 1개월치 데이터를 가져올 예정
(이름, 흥행지수, 순위, 출연자, 직업, 성별, 신장/체중, 취미 등등...)
2. 개발자도구 -> content클릭 -> Request URL에 있는 URL이 진짜 URL임. request로 가져올 때 저 URL사용해야함

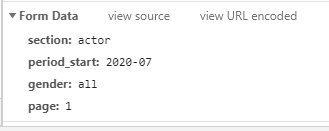
3. Post방식으로 전달하기 때문에 전달하는 Form Data값 확인(개발자도구 -> content클릭 -> 아래로 내리면 있음)
4. HTML돔 확인한 후 배우의 이름과 각 페이지 URL들을 가져오자!!

<Cine21 영화배우 정보 크롤링>
- site 주소 : http://www.cine21.com/rank/person
- 개발자 도구에서 XHR 인 것만 필터링 network -> content 페이지의 요청방식 확인
- Request URL : http://www.cine21.com/rank/person/content
- Request Method : Post
- Form Data (1개월치 데이터)
- section: actor
- period_start: 2020-07
- gender: all
- page: 1
- 1 ~ 2 년치 데이터를 한꺼번에 크롤링 해서 actor.json 파일로 저장하기
5. 영화배우 리스트가 나열된 페이지에서 각 배우의 이름, 링크 가져오기
import requests
from bs4 import BeautifulSoup
import re
import pymongo
from urllib.parse import urljoin
actor_url = 'http://www.cine21.com/rank/person/content'
formdata_dict = dict()
formdata_dict['section'] = 'actor'
formdata_dict['period_start'] = '2020-07'
formdata_dict['gender'] = 'all'
formdata_dict['page'] = 1
formdata_dict
res = requests.post(actor_url, data=formdata_dict)
#print(res.ok)
actor_item_list = list()
soup = BeautifulSoup(res.text,'html.parser')
for actor in soup.select('li.people_li div.name'):
print(actor.text)
print(re.sub('\(\w*\)','',actor.text))
for a_tag in soup.select('li.people_li div.name a'):
actor_link = urljoin(actor_url,a_tag['href'])
print(actor_link)

6. 각 배우의 URL을 뽑아냈으니 각 페이지에서 직업, 생년월일, 성별 등등의 정보를 가져와보자!!!

- 1단계
- 각 배우들의 개인 페이지 url들을 불러와서 개인 페이지 안에 있는 정보들을 출력
import requests
from bs4 import BeautifulSoup
import re
import pymongo
from urllib.parse import urljoin
actor_url = 'http://www.cine21.com/rank/person/content'
formdata_dict = dict()
formdata_dict['section'] = 'actor'
formdata_dict['period_start'] = '2020-07'
formdata_dict['gender'] = 'all'
formdata_dict['page'] = 1
formdata_dict
res = requests.post(actor_url, data=formdata_dict)
#print(res.ok)
actor_item_list = list()
soup = BeautifulSoup(res.text,'html.parser')
for actor in soup.select('li.people_li div.name'):
#print(actor.text)
re.sub('\(\w*\)','',actor.text)
for a_tag in soup.select('li.people_li div.name a'):
actor_link = urljoin(actor_url,a_tag['href'])
res = requests.get(actor_link)
soup = BeautifulSoup(res.text,'html.parser')
actor_item_dict = dict()
for li_tag in soup.select('ul.default_info li'):
# dict의 key에 해당하는 값을 추출한다. dict['직업]'
actor_item_field = li_tag.select_one('span.tit').text #직업
#dict의 value에 해당하는 값을 추출. dict['직업'] == '배우'
# <li><span class="tit">직업</span>배우</li>
actor_item_value = re.sub('<span.*?>.*?</span>','',str(li_tag)) #<li>배우</li>
actor_item_value = re.sub('<.*?>','',actor_item_value) #베우
'''적용전
\n https://gangdongwon.com
'''
regex = re.compile(r'[\n\r\t]')
actor_item_value = regex.sub('',actor_item_value)
'''적용후
https://gangdongwon.com
'''
actor_item_dict[actor_item_field] = actor_item_value
actor_item_list.append(actor_item_dict)
print(actor_item_list,len(actor_item_list))

- 2단계
- 1page의 7명의 배우 정보를 출력
import requests
from bs4 import BeautifulSoup
import re
import pymongo
from urllib.parse import urljoin
actor_url = 'http://www.cine21.com/rank/person/content'
formdata_dict = dict()
formdata_dict['section'] = 'actor'
formdata_dict['period_start'] = '2020-07'
formdata_dict['gender'] = 'all'
formdata_dict['page'] = 1
formdata_dict
res = requests.post(actor_url, data=formdata_dict)
soup = BeautifulSoup(res.text,'html.parser')
actor_item_list = list()
actors = soup.select('li.people_li div.name')
hits = soup.select('ul.num_info > li > strong')
movies = soup.select('ul.mov_list')
rankings = soup.select('li.people_li span.grade ')
# actor변수가 <div class=name>를 의미함
for index, actor in enumerate(actors):
actor_item_dict = dict()
#print(actor)
# 유아인(2편) 에서 (2편)을 제거하고 저장한다.
actor_name = re.sub('\(\w*\)','',actor.text)
actor_item_dict['배우이름'] = actor_name
# 흥행지수 값에서 ,(콤마)를 제거하고 정수타입으로 변환해서 저장한다.
actor_hit = int(hits[index].text.replace(',',''))
actor_item_dict['흥행지수'] = actor_hit
#출연작
movie_titles = movies[index].select('li a span')
#출연작 여러개의 title을 저장하는 리스트
movie_title_list = list()
for movie_title in movie_titles:
movie_title_list.append(movie_title.text)
actor_item_dict['출연영화'] = movie_title_list
#순위
actor_ranking = rankings[index].text
actor_item_dict['랭킹'] = int(actor_ranking)
#배우의 상세정보를 보기 위해 http get다시 요청
'''
<div class=name>
<a href="/db/person/info/?person_id=18040"> --> actor_detail_url
'''
actor_detail_url = actor.select_one('a').attrs['href']
actor_detail_full_url = urljoin(actor_url,actor_detail_url)
#print(actor_detail_full_url)
res = requests.get(actor_detail_full_url)
soup = BeautifulSoup(res.text,'html.parser')
for li_tag in soup.select('ul.default_info li'):
# dict의 key에 해당하는 값을 추출한다. dict['직업]'
actor_item_field = li_tag.select_one('span.tit').text #직업
#dict의 value에 해당하는 값을 추출. dict['직업'] == '배우'
# <li><span class="tit">직업</span>배우</li>
actor_item_value = re.sub('<span.*?>.*?</span>','',str(li_tag)) #<li>배우</li>
actor_item_value = re.sub('<.*?>','',actor_item_value) #베우
'''적용전
\n https://gangdongwon.com
'''
regex = re.compile(r'[\n\r\t]')
actor_item_value = regex.sub('',actor_item_value)
'''적용후
https://gangdongwon.com
'''
actor_item_dict[actor_item_field] = actor_item_value
actor_item_list.append(actor_item_dict)
print(actor_item_list,len(actor_item_list))
- 3단계
- 1,2,3 페이지의 21명 배우의 정보를 출력
import requests
from bs4 import BeautifulSoup
import re
import pymongo
from urllib.parse import urljoin
actor_url = 'http://www.cine21.com/rank/person/content'
formdata_dict = dict()
formdata_dict['section'] = 'actor'
formdata_dict['period_start'] = '2020-07'
formdata_dict['gender'] = 'all'
actor_item_list = list()
for page in range(1,4):
formdata_dict['page'] = page
print('----> {}페이지'.format(page))
res = requests.post(actor_url, data=formdata_dict)
soup = BeautifulSoup(res.text,'html.parser')
actors = soup.select('li.people_li div.name')
hits = soup.select('ul.num_info > li > strong')
movies = soup.select('ul.mov_list')
rankings = soup.select('li.people_li span.grade ')
# actor변수가 <div class=name>를 의미함
for index, actor in enumerate(actors):
print('==> {} 번째 배우 출력'.format(index))
actor_item_dict = dict()
#print(actor)
# 유아인(2편) 에서 (2편)을 제거하고 저장한다.
actor_name = re.sub('\(\w*\)','',actor.text)
actor_item_dict['배우이름'] = actor_name
# 흥행지수 값에서 ,(콤마)를 제거하고 정수타입으로 변환해서 저장한다.
actor_hit = int(hits[index].text.replace(',',''))
actor_item_dict['흥행지수'] = actor_hit
#출연작
movie_titles = movies[index].select('li a span')
#출연작 여러개의 title을 저장하는 리스트
movie_title_list = list()
for movie_title in movie_titles:
movie_title_list.append(movie_title.text)
actor_item_dict['출연영화'] = movie_title_list
#순위
actor_ranking = rankings[index].text
actor_item_dict['랭킹'] = int(actor_ranking)
#배우의 상세정보를 보기 위해 http get다시 요청
'''
<div class=name>
<a href="/db/person/info/?person_id=18040"> --> actor_detail_url
'''
actor_detail_url = actor.select_one('a').attrs['href']
actor_detail_full_url = urljoin(actor_url,actor_detail_url)
#print(actor_detail_full_url)
res = requests.get(actor_detail_full_url)
soup = BeautifulSoup(res.text,'html.parser')
for li_tag in soup.select('ul.default_info li'):
# dict의 key에 해당하는 값을 추출한다. dict['직업]'
actor_item_field = li_tag.select_one('span.tit').text #직업
#dict의 value에 해당하는 값을 추출. dict['직업'] == '배우'
# <li><span class="tit">직업</span>배우</li>
actor_item_value = re.sub('<span.*?>.*?</span>','',str(li_tag)) #<li>배우</li>
actor_item_value = re.sub('<.*?>','',actor_item_value) #베우
'''적용전
\n https://gangdongwon.com
'''
regex = re.compile(r'[\n\r\t]')
actor_item_value = regex.sub('',actor_item_value)
'''적용후
https://gangdongwon.com
'''
actor_item_dict[actor_item_field] = actor_item_value
actor_item_list.append(actor_item_dict)
#print(actor_item_list,len(actor_item_list))
print(actor_item_list,len(actor_item_list))
4단계
- 1년치 데이터 1905명 배우의 정보를 출력
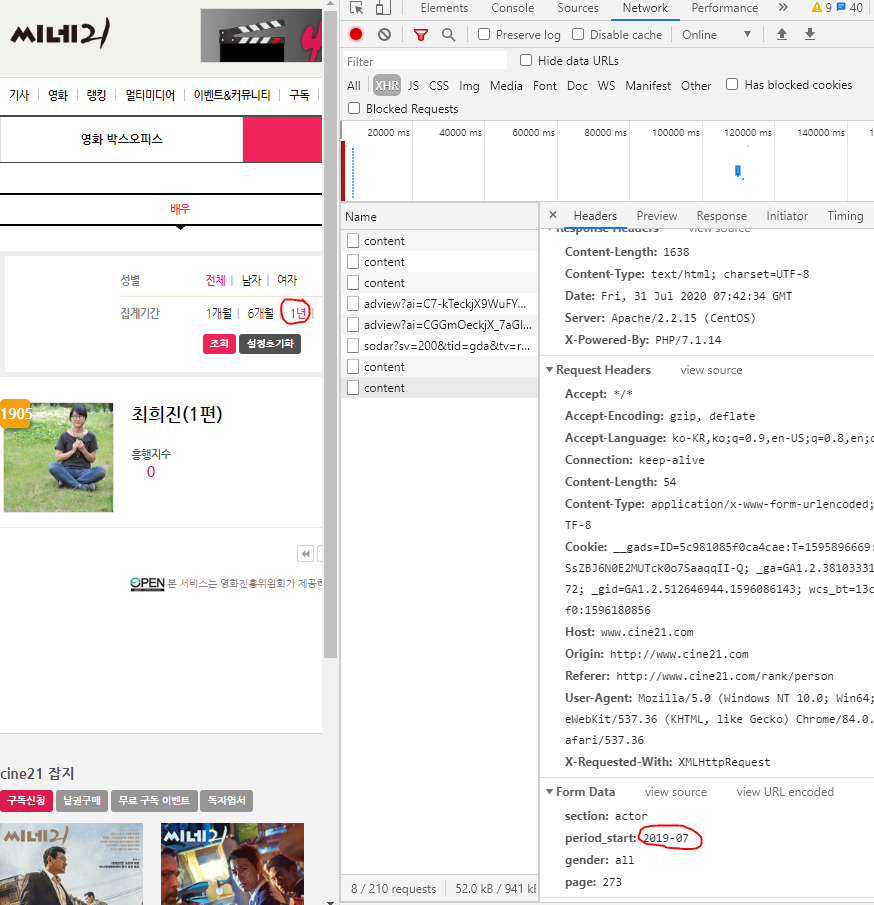
- 1년치 데이터를 클릭한 후 개발자도구를 보면 form Data 에 period_start가 2020년 -> 2019년으로 변경된 것을 볼 수 있다.
import requests
from bs4 import BeautifulSoup
import re
import pymongo
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
import re
import pymongo
from urllib.parse import urljoin
from itertools import count
actor_url = 'http://www.cine21.com/rank/person/content'
formdata_dict = dict()
formdata_dict['section'] = 'actor'
formdata_dict['period_start'] = '2019-07'
formdata_dict['gender'] = 'all'
actor_item_list = list()
for page in count(1):
formdata_dict['page'] = page
print('----> {}페이지'.format(page))
res = requests.post(actor_url, data=formdata_dict)
soup = BeautifulSoup(res.text,'html.parser')
actors = soup.select('li.people_li div.name')
if len(actors) == 0:
break
hits = soup.select('ul.num_info > li > strong')
movies = soup.select('ul.mov_list')
rankings = soup.select('li.people_li span.grade ')
# actor변수가 <div class=name>를 의미함
for index, actor in enumerate(actors):
actor_item_dict = dict()
#print(actor)
# 유아인(2편) 에서 (2편)을 제거하고 저장한다.
actor_name = re.sub('\(\w*\)','',actor.text)
actor_item_dict['배우이름'] = actor_name
print('==> {}({}) 배우 출력'.format(actor_name,len(actor_name)))
# 흥행지수 값에서 ,(콤마)를 제거하고 정수타입으로 변환해서 저장한다.
actor_hit = int(hits[index].text.replace(',',''))
actor_item_dict['흥행지수'] = actor_hit
#출연작
movie_titles = movies[index].select('li a span')
#출연작 여러개의 title을 저장하는 리스트
movie_title_list = list()
for movie_title in movie_titles:
movie_title_list.append(movie_title.text)
actor_item_dict['출연영화'] = movie_title_list
#순위
actor_ranking = rankings[index].text
actor_item_dict['랭킹'] = int(actor_ranking)
#배우의 상세정보를 보기 위해 http get다시 요청
'''
<div class=name>
<a href="/db/person/info/?person_id=18040"> --> actor_detail_url
'''
actor_detail_url = actor.select_one('a').attrs['href']
actor_detail_full_url = urljoin(actor_url,actor_detail_url)
#print(actor_detail_full_url)
res = requests.get(actor_detail_full_url)
soup = BeautifulSoup(res.text,'html.parser')
for li_tag in soup.select('ul.default_info li'):
# dict의 key에 해당하는 값을 추출한다. dict['직업]'
actor_item_field = li_tag.select_one('span.tit').text #직업
#dict의 value에 해당하는 값을 추출. dict['직업'] == '배우'
# <li><span class="tit">직업</span>배우</li>
actor_item_value = re.sub('<span.*?>.*?</span>','',str(li_tag)) #<li>배우</li>
actor_item_value = re.sub('<.*?>','',actor_item_value) #베우
'''적용전
\n https://gangdongwon.com
'''
regex = re.compile(r'[\n\r\t]')
actor_item_value = regex.sub('',actor_item_value)
'''적용후
https://gangdongwon.com
'''
actor_item_dict[actor_item_field] = actor_item_value
actor_item_list.append(actor_item_dict)
#print(actor_item_list,len(actor_item_list))
print(actor_item_list,len(actor_item_list))
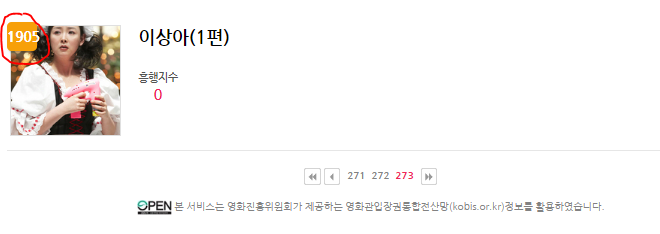
- 총 갯수가 1905개로 전체 다 나온것을 확인할 수 있었다.

- 배우 이름이 10글자 이하인 것만 출력하니 1903개가 나온것을 확인할 수 있었다.

- 배우이름이 10개 이상으로 나온 2개의 데이터가 존재하는 이유는 다음과 같이 오류가 있었기 때문이다.

- selector를 통해 데이터를 추출한 결과가 어떤식으로 출력되는지 궁금할 경우 참조 바람

2. 정규표현식
- \w 는 문자와 숫자
- * : 0 ~ n (횟수), + : 1 ~ n, ? : 0(zero) or 1
- . (period) : 줄바꿈 문자(\n)을 제외한 모든 글자 1개를 의미한다.
- .* 는 문자가 0번 또는 그 이상 반복되는 패턴
- Greedy( .* ) vs Non-Greedy( .*? )
- Greedy( .* ) (욕심많은) : 모두 선택됨
- Non-Greedy( .*? ) (욕심없는) : 첫번째 매칭되는 태그만
- [\n\r\t] : \n,\r,\t중 하나를 찾는다.
- re.compile(r'[\n\r\t]')는 해당 정규표현식을 찾아주는 컴파일러를 생성해주는 함수이다.
- compile 함수내의 정규표현식 앞에 항상 r을 붙여주어야 한다.
test_data ='유아인(2편)'
re.sub('\(\w*\)','',test_data) #결과 : '유아인'
test_data = """홈페이지
http://www.gangdongwon.com
신장/체중"""
regex = re.compile(r'[\n\r\t]')
regex.sub('',test_data)

- 최종 json 파일
'Python > Python 웹 크롤링' 카테고리의 다른 글
| Selenium (0) | 2020.07.29 |
|---|---|
| 파이썬 OpenAPI_07월 24일 (0) | 2020.07.24 |
| 파이썬 OpenAPI_07월 23일 (0) | 2020.07.23 |
| 파이썬 OpenAPI_07월 22일 (0) | 2020.07.22 |
| 파이썬 OpenAPI_07월 21일 (0) | 2020.07.21 |