
- 2차원 배열
# 2차원 배열
# 학생별 과목의 평균을 계산
kor_score = [49, 79, 20, 100, 80]
math_score = [43, 59, 85, 30, 90]
eng_score = [49, 79, 48, 60, 100]
midterm_score = [kor_score, math_score, eng_score]
print(midterm_score[0][2])
- 제어문
- 다른 언어와 다른게 else if 가 아닌 elif 사용
- 문제 :

- 풀이
from datetime import datetime as dt
nowyear = dt.today().year
print('당신이 태어난 년도를 입력해주세요')
born_year = int(input())
old = nowyear - born_year + 1
if 17 <= old < 20:
print('당신은 고등학생 입니다.')
elif 20 <= old < 27:
print('당신은 대학생 입니다.')
else: print('당신은 학생이 아닙니다.')
- for in range
# for-in 구문 사용
for val in [0, 1, 2]:
print(val)
# range(start, end, 증가치)함수
# start의 default값은 0
# end는 exclusive하며, 항상 end -1
for val in range(0, 10):
print(val, end='')
for val in range(0, 10, 2):
print(val)
favor_hobby = ['finishing', 'reading', 'shopping']
for hobby in favor_hobby:
print(hobby)
- dictionary
# dict 타입
wish_travel_city = {'bangkok':'Thai',
'LA':'USA',
'Seoul':'Korea',
'bangkok':'ThaiLand'}
print(wish_travel_city)
print(wish_travel_city["LA"]) #USA
print(wish_travel_city["bangkok"]) #ThaiLand
#--> 같은 키값이 두개 있으면 둘중 어떤 값이 사용될 지 모른다. -> 같은 키값을 사용하면 안된다.
# key와 value를 출력할 때 keys 함수 사용
for city in wish_travel_city.keys():
print('결과는 : {} in {}'.format(city, wish_travel_city[city]))
'''
결과는 : bangkok in ThaiLand
결과는 : LA in USA
결과는 : Seoul in Korea
'''
# items는 key와 value 둘 다 꺼내옴
for city, country in wish_travel_city.items():
print(f'{city} in {country}')
- random
import random 추가해야함
for val in range(1, 11):
ticket = random.randint(1, 100)
print(f'index{val}: random value {ticket}')
- while문
#for문
for val in range(0, 10):
print(val)
# for -> while 변경
idx = 0
while idx < 10:
print(idx)
idx += 1
- break, continue 차이
print('break~~~~~~')
for val in range(10):
if val == 5:
break
print(val)
# 1 2 3 4
print('continue~~~~~~')
for val in range(10):
if val == 5:
continue
print(val)
# 1 2 3 4 6 7 8 9
- 연습문제(Guess Game)

- 풀이
import random
print('1~100까지의 아무 숫자나 입력해줏요~!')
# 1~100까지의 랜덤 숫자
guess_number = random.randint(1, 100)
# 사용자로부터 숫자 입력받기
user_number = int(input())
# 랜덤 숫자와 입력받은 숫자가 같으면 game 종료
# 정답 알려줌, 몇 번 만에 맞췄는지 알려줌
count = 0
while guess_number != user_number:
# 입력 받은 숫자 > 랜덤숫자 -> '숫자가 너무 큽니다.'
# 입력 받은 숫자 < 랜덤숫자 -> '숫자가 너무 작습니다.'
if user_number > guess_number:
print('숫자가 너무 큽니다.')
elif user_number < guess_number:
print('숫자가 너무 작습니다.')
count += 1
user_number = int(input())
else:
print(f'정답은 {guess_number} 입니다.')
print(f'당신은 정답을 {count} 번 만에 맞췄습니다.')
- 연습문제(구구단)

- 풀이
print('구구단 몇 단을 계산할까요(1~9)?')
dan_num = int(input())
while(dan_num is not 0):
for j in range(10):
print(f'{dan_num} X {j} = {dan_num*j}')
print('구구단 몇 단을 계산할까요(1~9)?')
dan_num = int(input())
else:
print('구구단 게임을 종료합니다.')
- 문제 : 2차원 배열 문제

- 풀이
# 2차원 배열
# 학생별 과목의 평균을 계산
kor_score = [49, 79, 20, 100, 80]
math_score = [43, 59, 85, 30, 90]
eng_score = [49, 79, 48, 60, 100]
midterm_score = [kor_score, math_score, eng_score]
# 학생별 과목의 합계를 저장할 리스트
# 중첩된 for 루프 안에서 학생별 과목 점수 합계를 저장한다.
student_score = [0, 0, 0, 0, 0]
# 학생을 구분하기 위한 인덱스
idx = 0 # 이부분 중요!!!
for subject in midterm_score:
for student in subject:
print(student)
student_score[idx] += student
idx += 1 # 이부분 중요!!!
print('-------')
idx = 0 # 이부분 중요!!!
else :
print(student_score)
# 학생별 점수를 unpacking
a, b, c, d, e, = student_score
student_average = [int(a/3), int(b/3), int(c/3), int(d/3), int(e/3)]
print(student_average)
- 자료구조
- 자료구조란 ? 메모리 상에서 데이터를 효율적으로 관리하는 방법 -> 실행시간 최소화 위해
- 파이썬에는 List, Tuple, Set, Dictionary등의 기본 데이터 구조 제공
- Stack & Queue
* 스택 : LIFO
* 큐 : FIFO
# Stack - LIFO
my_stack = [20, 10, 30, 40, 20]
print(my_stack) #결과 : [20, 10, 30, 40, 20]
my_stack.append(100)
print(my_stack) #결과 : [20, 10, 30, 40, 20, 100]
print(my_stack.pop()) #결과 : 100
#입력 : 1 2 3 4 5
#출력 : 5 4 3 2 1
word = input("Input a word : ")
word_list = list(word)
for i in range(len(word_list)):
print(word_list.pop())
# Queue - FIFO
print(my_stack.pop(0)) #결과 : 20
print(my_stack) #결과 : [10, 30, 40, 20]
my_stack.append(30)
print(my_stack) #결과 : [10, 30, 40, 20, 30]
- 튜플
* List와 역할이 같지만 Read Only(수정안됨)
my_stack = [20, 10, 30, 40, 20]
# Tuple
print(my_stack) #결과 : [20, 10, 30, 40, 20]
my_stack.append(30)
print(set(my_stack)) #결과 : {40, 10, 20, 30}
my_tuple = tuple(my_stack)
print(type(my_tuple), my_tuple) #결과 : <class 'tuple'> (20, 10, 30, 40, 20, 30)
# my_tuple[0] = 50 # 에러 : TypeError: 'tuple' object does not support item assignment
print(my_tuple * 2) #결과 : (20, 10, 30, 40, 20, 30, 20, 10, 30, 40, 20, 30)
print(len(my_tuple)) #결과 : 6
my_int = (1)
print(type(my_int), my_int) #결과 : <class 'int'> 1
my_tuple2 = (1,)
print(type(my_tuple2), my_tuple2) #<class 'tuple'> (1,)
- Set
* 중복 허용 X
* 순서 X
# Set
my_set = set([40, 20, 49, 50, 20, 50])
print(my_set) # 결과 : {40, 49, 50, 20}
my_set.add(49)
print(my_set) # 결과 : {40, 49, 50, 20} - 이미 49가 있기 때문에 무시됨
my_set.remove(49)
print(my_set) # 결과 : {40, 50, 20}
my_set.discard(20)
print(my_set) # 결과 : {40, 50}
my_set.discard(10)
print(my_set) # 결과 : {40, 50}
my_set.remove(10)
print(my_set)* discard 와 remove 차이
: discard - 존재하지 않는 값 삭제시 그냥 무시됨
remove - 존재하지 않는 값 삭제시 Exception(KeyError) 발생시킴
* 집합연산(합집합, 교집합, 차집합)
s1 = set([1, 2, 3, 4, 5])
s2 = set([3, 4, 5, 6, 7])
print(s1.union(s2)) #합집합
print(s1.intersection(s2)) #교집합
print(s1.difference(s2)) #차집합
- Dictionary
# Dict
my_dict = {} #Dict생성방법1
my_dict2 = dict() #Dict생성방법2
print(type(my_dict), type(my_dict2))
my_dict['java'] ='자바'
my_dict['python'] = '파이썬'
my_dict['javascript'] = '자바스크립트'
print(my_dict)
print(my_dict['java'])
#print(my_dict['python1']) #매칭되는 key값이 없으면 KeyError발생
print(my_dict.get('python1')) #매칭되는 key값이 없으면 None 반환
# None반환을 통해 조건문 사용
value = my_dict.get('python1')
if value :
print(value)
else:
print('해당 key가 존재하지 않습니다')
# 해당 키 삭제
del my_dict['python']
print(my_dict)
# in 구문을 사용해서 해당 key 있는지를 체크
print('java' in my_dict)
# Keys(), values(), items()
print(my_dict.keys())
print(my_dict.values())
print(my_dict.items()) #튜플 형태로 반환
- ZIP() 함수
# zip() 함수 사용하기
days = ['월요일', '화요일', '수요일']
coffees = ['아메리카노', '라떼', '바닐라', '녹차']
for day, coffee in zip(days, coffees):
print(f'{day}에는 {coffee}를 마셔요')
'''
결과 :
월요일에는 아메리카노를 마셔요
화요일에는 라떼를 마셔요
수요일에는 바닐라를 마셔요
'''* Zip(), range()와 같은 함수 - Iterable객체 반환 - 출력시 object로 나와 값 확인 불가
-> for문 돌려 값 확인 OR lsit / dict 에 넣어 값 확인 가능
# zip() 함수 사용하기
days = ['월요일', '화요일', '수요일']
coffees = ['아메리카노', '라떼', '바닐라', '녹차']
print(zip(days, coffees)) #결과 : <zip object at 0x000001E6C2CA9208>
print(list(zip(days, coffees))) #결과 : [('월요일', '아메리카노'), ('화요일', '라떼'), ('수요일', '바닐라')]
print(dict(zip(days, coffees))) #결과 : {'월요일': '아메리카노', '화요일': '라떼', '수요일': '바닐라'}
- setdefault() 함수
딕셔너리에 값 추가시 해당 키가 없으면 추가해줌
# setdefault() 함수
print(my_dict) # 결과 : {'java': '자바', 'javascript': '자바스크립트'}
my_dict.setdefault('python', '파이썬')
print(my_dict) # 결과 : {'java': '자바', 'javascript': '자바스크립트', 'python': '파이썬'}
my_dict.setdefault('python', '추가될까?')
print(my_dict) # 결과 : {'java': '자바', 'javascript': '자바스크립트', 'python': '파이썬'}
- python coding convention
- 공백 4칸
- 함수명은 소문자, 두단어는 밑줄(snake style)
- 소문자 l(엘), 대문자 O, 대문자 I(아이) 금지
- 불필요한 주석 삭제 등등 ...
- flake8 모듈로 기준을 체크할 수 있다.
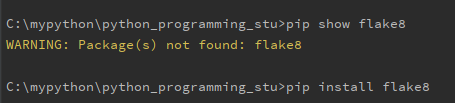

- 함수
- Parameter vs Argument
parameter : 함수의 입력 값 인터페이스(인자가 한개다 두개다.. 이런거) ex) def f(x):
Argument : 실제 parameter에 대입된 값 ex) print(f(2))
- def로 시작, 들여쓰기로 구분
- 지역변수 vs 전역변수
지역변수 : 함수 내부에서만 사용
전역변수 : 프로그램 전체에서 사용
BUT 이름이 같은 지역, 전역 변수가 있을 때 지역변수가 우선됨. 가급적이면 지역, 전역 변수 같은이름 사용하지 않도록
# 평균을 계산하는 함수를 정의
def my_average(numbers):
# local variable
total = 0
for num in numbers:
total += num
my_avg = total / len(numbers)
return my_avg
def main():
prices = [1000, 3000, 2500, 450]
result = my_average(prices)
print(result) #결과 : 1737.5
main()
# 함수 외부에서는 로컬변수를 사용할 수 없음
# print(total)
- 함수 파라미터_위치 파라미터
def connect(server, port):
#pass # 함수는 선언했지만 구현내용을 나중에 하고싶은 경우 pass 키워드 사용 (구현 안할 경우 컴파일 에러)
return 'https://{}:{}'.format(server, port)
def main():
result2 = connect('server.com', '9080')
print(result2) #결과 : https://server.com:9080
result2 = connect(port='8087', server='aa.com')
print(result2) #결과 : https://aa.com:8087
main()
- 함수 파라미터_기본 파라미터 값 지정
def times(n1 = 10, n2 = 20):
return n1*n2
def main():
result3 = times()
print(result3) #결과 : 200
result3 = times(2)
print(result3) #결과 : 40
result3 = times(3, 4)
print(result3) #결과 : 12
main()
- 함수 파라미터_가변 파라미터(tuple type, dict type)
# *p - tuple type parameter, 아규먼트의 갯수가 가변적
def var_param(*p):
return p
# **p - dict type parameter
def var_param_dict(**p):
return p
def main():
result4 = var_param(1,2,3,4,2,4,)
print(type(result4), result4) #결과 : <class 'tuple'> (1, 2, 3, 4, 2, 4)
result5 = var_param_dict(a=1, b=2, c=90)
print(type(result5), result5) #결과 : <class 'dict'> {'a': 1, 'b': 2, 'c': 90}
main()def tuple_dict_param(n1, n2, *n3, **n4):
print(n1, n2, sum(n3))
print(n4)
def main():
tuple_dict_param(1, 2, 3, 4, 5, 6, 7, a=23, b=45) #결과 : 1 2 25 {'a': 23, 'b': 45}
- 다중 return
: 파이썬은 다중값을 리턴값으로 전달 가능(실제 튜플에 저장되어 리턴 됨)
# 다중 값을 리턴하는 함수
def swap(a, b):
return b, a
def main():
result6 = swap(1, 2)
print(type(result6), result6) #결과 : <class 'tuple'> (2, 1)
x, y = result6 #unpacking
print(x, y) #결과 : 2 1
'Python > Python 웹 크롤링' 카테고리의 다른 글
| 파이썬 OpenAPI_07월 21일 (0) | 2020.07.21 |
|---|---|
| 파이썬 OpenAPI_07월 20일 (0) | 2020.07.20 |
| 파이썬 수업_07월 17일 (0) | 2020.07.17 |
| 파이썬 수업_07월 16일 (0) | 2020.07.16 |
| 파이썬 설치 및 특징 (0) | 2020.07.14 |