
- 함수 작성 가이드라인
- 함수는 가능하면 짧게 작성
- 함수 이름에 역할, 의도가 명확이 들어나도록
- 하나의 함수에는 유사한 역할을 하는 코드만 작성
- 인자로 받은 값 자체를 바꾸진 말 것
- 공통 코드 -> 함수로 변환
- 복잡한 수식 -> 함수로 변환
- Pythonic Code 작성하기
- 파이썬 스타일의 코딩 기법(간결)
- Join 함수
# Join() 함수
colors = ['red', 'yellow', 'green']
result = ','.join(colors)
print(result) #결과 : red,yellow,green- Split함수
# Split() 함수
langs = 'python,java,c#,sclar'
result = langs.split(',')
print(type(result), result) #결과 : <class 'list'> ['python', 'java', 'c#', 'sclar']
a, b, c, d = langs.split(',') #unpacking(유의사항:갯수맞춰야함)
print(a, b, c, d)
langs = 'python java c# sclar'
result = langs.split() #공백은 구분자 안줘도 됨
print(type(result), result) #결과 : <class 'list'> ['python', 'java', 'c#', 'sclar']
- List Comprehensions
1. List Comprehensions(포괄적인 리스트)
* 1~10까지의 숫자
# 일반적인 for loop
my_list = []
for val in range(10):
my_list.append(val)
print(my_list) #결과 : [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# List Comprehensions(포괄적인 리스트)
my_list2 = [val for val in range(10)]
print(my_list2) #결과 : [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]* 1~10까지의 짝수
# 일반적인 for loop
my_list = []
for val in range(10):
if val % 2 == 0:
my_list.append(val)
print(my_list) #결과 : [0, 2, 4, 6, 8]
# List Comprehensions(포괄적인 리스트)
my_list2 = [val for val in range(10) if val % 2 == 0]
print(my_list2) #결과 : [0, 2, 4, 6, 8]
my_list3 = [val if val % 2 == 0 else 10 for val in range(10)]
print(my_list3) #결과 : [0, 10, 2, 10, 4, 10, 6, 10, 8, 10]2. 문자열 타입 List Comprehension
word1 = 'Hello'
word2 = 'World'
# for i in word1:
# for j in word2:
# print(i+j)
my_list4 = [i+j for i in word1 for j in word2]
print(my_list4) # 결과 : ['HW', 'Ho', 'Hr', 'Hl', 'Hd', 'eW', 'eo', 'er', 'el', 'ed', 'lW', 'lo', 'lr', 'll', 'ld', 'lW', 'lo', 'lr', 'll', 'ld', 'oW', 'oo', 'or', 'ol', 'od']
my_list5 = [i+j for i in word1 for j in word2 if i==j]
print(my_list5) # 결과 : ['ll', 'll', 'oo']
3. 2차원 배열 타입 List Comprehensions
# 일반적 방법
result_list = []
for w in words:
word_list = [w.upper(), w.lower(), len(w)]
result_list.append(word_list)
print(result_list) # 결과 : [['YESTERDAY', 'yesterday', 9], ['LOVE', 'love', 4], ['WAS', 'was', 3], ['SUCH', 'such', 4], ['AN', 'an', 2], ['EASY', 'easy', 4], ['GAME', 'game', 4], ['TO', 'to', 2], ['PLAY', 'play', 4]]
# 2차원 배열 형 List Comprehensions
stuff = [[w.upper(), w.lower(), len(w)] for w in words]
print(stuff) # 결과 : [['YESTERDAY', 'yesterday', 9], ['LOVE', 'love', 4], ['WAS', 'was', 3], ['SUCH', 'such', 4], ['AN', 'an', 2], ['EASY', 'easy', 4], ['GAME', 'game', 4], ['TO', 'to', 2], ['PLAY', 'play', 4]]
- 연습문제

- 풀이
(일반적 방법 - 내가 푼 방법)
books = list()
books.append({'제목':'개발자의 코드', '출판연도':'2013.02.28', '출판사':'A출판','쪽수':200,'추천유무':False})
books.append({'제목':'클린 코드', '출판연도':'2013.03.04', '출판사':'B출판','쪽수':584,'추천유무':True})
books.append({'제목':'빅데이터 마케팅', '출판연도':'2014.07.02', '출판사':'A출판','쪽수':296,'추천유무':True})
books.append({'제목':'구글드', '출판연도':'2010.02.10', '출판사':'B출판','쪽수':526,'추천유무':False})
books.append({'제목':'강의력', '출판연도':'2013.12.12', '출판사':'C출판','쪽수':248,'추천유무':True})
print(books)
# 일반적 방법
# 250쪽 넘는 책 목록 만들기
pages_list = []
idx = 0
for book in books:
pages = book['쪽수']
#print(pages)
if pages > 250:
pages_list.append(books[idx])
idx += 1
else:
idx += 1
print(pages_list)
'''
결과 :
[{'제목': '클린 코드', '출판연도': '2013.03.04', '출판사': 'B출판', '쪽수': 584, '추천유무': True}, {'제목': '빅데이터 마케팅', '출판연도': '2014.07.02', '출판사': 'A출판', '쪽수': 296, '추천유무': True}, {'제목': '구글드', '출판연도': '2010.02.10', '출판사': 'B출판', '쪽수': 526, '추천유무': False}]
'''
# 추천유무가 True인 책 목록 만들기
recomm_list = []
idx = 0
for book in books:
recomm_exist = book['추천유무']
#print(recomm_exist)
if recomm_exist is True:
recomm_list.append(books[idx])
idx += 1
else:
idx += 1
print(recomm_list)
'''
결과 :
[{'제목': '클린 코드', '출판연도': '2013.03.04', '출판사': 'B출판', '쪽수': 584, '추천유무': True}, {'제목': '빅데이터 마케팅', '출판연도': '2014.07.02', '출판사': 'A출판', '쪽수': 296, '추천유무': True}, {'제목': '강의력', '출판연도': '2013.12.12', '출판사': 'C출판', '쪽수': 248, '추천유무': True}]
'''
# 출판사 목록 만들기
title_list = []
pub_com = set()
for book in books:
publish = book['출판사']
title_list.append(publish)
pub_com = set(title_list)
print(pub_com)
'''
결과 :
{'B출판', 'A출판', 'C출판'}
'''(일반적 방법 - 강사님 풀이)
books = list()
books.append({'제목':'개발자의 코드', '출판연도':'2013.02.28', \
'출판사':'A출판', '쪽수':200, '추천유무':False})
books.append({'제목':'클린 코드', '출판연도':'2013.03.04', \
'출판사':'B출판', '쪽수':584, '추천유무':True})
books.append({'제목':'빅데이터 마케팅', '출판연도':'2014.07.02', \
'출판사':'A출판', '쪽수':296, '추천유무':True})
books.append({'제목':'구글드', '출판연도':'2010.02.10', \
'출판사':'B출판', '쪽수':526, '추천유무':False})
books.append({'제목':'강의력', '출판연도':'2013.12.12', \
'출판사':'C출판', '쪽수':248, '추천유무':True})
# [{}, {}, {}]
#print(books)
# 책제목 리스트
title_list = list()
# 출판사 리스트
pub_comp = set()
# 쪽수가 250 초과인 리스트
many_page_list = list()
# 추천유무가 True인 리스트
recommend_list = list()
# 전체 페이지수
all_pages = int()
for book in books:
#print(type(book), book['제목'])
title_list.append(book['제목'])
pub_comp.add(book['출판사'])
# 쪽수가 250 초과
if book['쪽수'] > 250:
many_page_list.append(book['제목'])
if book['추천유무']:
recommend_list.append(book['제목'])
#all_pages += book['쪽수']
all_pages = all_pages + book['쪽수']
# print(title_list)
# print(pub_comp)
# print(many_page_list)
# print(recommend_list)
# print(all_pages)
(List Comprehensions 방법)
books = list()
books.append({'제목':'개발자의 코드', '출판연도':'2013.02.28', '출판사':'A출판','쪽수':200,'추천유무':False})
books.append({'제목':'클린 코드', '출판연도':'2013.03.04', '출판사':'B출판','쪽수':584,'추천유무':True})
books.append({'제목':'빅데이터 마케팅', '출판연도':'2014.07.02', '출판사':'A출판','쪽수':296,'추천유무':True})
books.append({'제목':'구글드', '출판연도':'2010.02.10', '출판사':'B출판','쪽수':526,'추천유무':False})
books.append({'제목':'강의력', '출판연도':'2013.12.12', '출판사':'C출판','쪽수':248,'추천유무':True})
# list comprehensions
# 출판사 목록 만들기
pub_com = set()
pub_com = set([book['출판사'] for book in books])
print(pub_com)
# 추천유무가 True인 책 목록 만들기
recomm_exist = []
recomm_exist = [book['제목'] for book in books if book['추천유무'] is True]
print(recomm_exist)
# 250쪽 넘는 책 목록 만들기
pages_list = []
pages_list = [book['제목'] for book in books if book['쪽수'] > 250]
print(pages_list)
# 모든 쪽수의 합
all_pages = []
all_pages = sum(book['쪽수'] for book in books)
print(all_pages)
- Enumerate
# indexed traversal
langs_list = 'python java c# sclar'.split()
# Bad
for idx in range(len(langs_list)):
print(f'idx = {idx}, values = {langs_list[idx]}')
# Good - enumerable() 함수
for idx, lang in enumerate(langs_list):
print(f'idx = {idx}, values = {lang}')
'''
결과 :
idx = 0, values = python
idx = 1, values = java
idx = 2, values = c#
idx = 3, values = sclar
'''iterator형식으로 출력되기 때문에
print(enumerate(langs_list)) --> 값 확인 못해 / 결과 : <enumerate object at 0x0000019DCCF42818>
print(list(enumerate(langs_list))) --> list로 변환하여 확인 가능 / 결과 : [(0, 'python'), (1, 'java'), (2, 'c#'), (3, 'sclar')]
# Dict Comprehensions
my_dict = {idx:val for idx,val in enumerate('Yesterday love was such an easy game to play'.split())}
print(my_dict)
#결과 : {0: 'Yesterday', 1: 'love', 2: 'was', 3: 'such', 4: 'an', 5: 'easy', 6: 'game', 7: 'to', 8: 'play'}
- 기타
# Variable Exchange
a = 10
b = 20
tmp = a
a = b
b = tmp
print(a, b) #결과 : 20 10
# good
a = 10
b = 20
a, b = b, a
print(a, b) # 결과 : 20 10# Sequence Unpacking
a, *rest = [1, 2, 3]
print(a, type(rest), rest) # 결과 : 1 <class 'list'> [2, 3]
a, *middle, c = [1, 2, 3, 4]
print(a, middle, c) # 결과 : 1 [2, 3] 4# Judgement T, F
# Bad
attr = True
if attr == True:
pass
# Good
if attr:
pass# Bad
attr = None
if attr == None:
pass
# Good
if attr is None:
pass- zip
# zip() 함수
a, b, c = zip((1, 2, 3), (10, 20, 30), (100, 200, 300))
print(a, b, c) #(1, 10, 100) (2, 20, 200) (3, 30, 300)
for val in zip((1, 2, 3), (10, 20, 30), (100, 200, 300)):
print(val)
'''
(1, 10, 100)
(2, 20, 200)
(3, 30, 300)
'''
# index가 같은 값을 tupple로 믂어서 합을 계산하고 List에 저장함
sum_list = [sum(val) for val in zip((1, 2, 3), (10, 20, 30), (100, 200, 300))]
print(sum_list) #[111, 222, 333]# Enumerate & Zip
a_list = ['a1', 'a2', 'a3']
b_list = ['b1', 'b2', 'b3']
for i, (a, b) in enumerate(zip(a_list, b_list)):
print(i, a, b)
'''
0 a1 b1
1 a2 b2
2 a3 b3
'''
- 람다식
- 함수 안에 인자로 함수가 들어갈 경우 복잡 --> 람다식 사용하면 간결 + 간편
# 일반적인 함수 정의
def add(x,y):
return x + y
print(add(10,20))
# lambda 함수 정의
add2=lambda x, y: x + y
print(add2(10, 20))
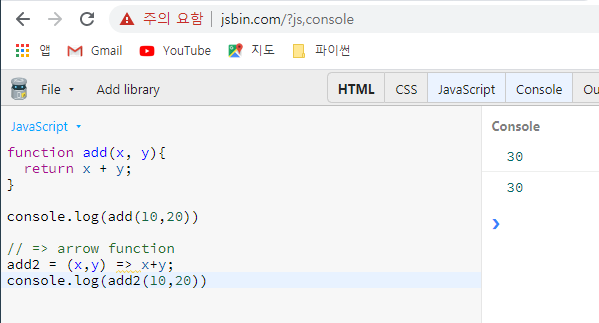
- javascript에서의 람다 식 (jsbin.com 홈페이지에서 자바스크립트 실행 가능)
* javascript에서는 => 사용, arrow함수 라고 함
- javascript map() 함수
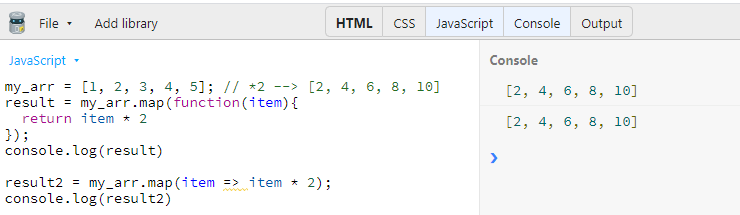
이런 함수를 call back 함수라고 부름
- 파이썬 map() 함수
# Map() 함수
my_arr = [1, 2, 3, 4, 5]
result = map(lambda x: x * 2, my_arr)
print(result)#<map object at 0x00000243D8449C48>
print(list(result))#[2, 4, 6, 8, 10]
result = list(map(lambda x: x*2, my_arr))
print(result)#[2, 4, 6, 8, 10]# [1, 2, 3, 4, 5] + [1, 2, 3, 4, 5]
# add(1, 1) add(2, 2) add(3, 3)....
f_add = lambda x, y: x + y
print(f_add(1, 1))#2
result = list(map(f_add, my_arr, my_arr))
print(result)#[2, 4, 6, 8, 10]
- 예제
# my_arr 리스트의 값을 제곱승 해서 다른 리스트에 저장하세요
# lambda 함수와 map() 함수 사용합니다.
result = list(map(lambda x: x**2, my_arr))
print(result) #[1, 4, 9, 16, 25]
- next
# 값을 차례로 한개씩 가져오는 함수 -> list안에서는 동작 안함
f_pow = lambda x: x**2
result = map(f_pow, my_arr)
print(next(result))
print(next(result))
print(next(result))
print(next(result))
print(next(result))
- filter(javascript)

- filter(python)
# Filter 함수
result = filter(lambda x: x > 2, my_arr)
print(result) #<filter object at 0x000001C210DCD308>
print(list(result)) #[3, 4, 5]
for val in filter(lambda x: x > 2, my_arr):
print(val) # 3 4 5
- reduce(javascript)
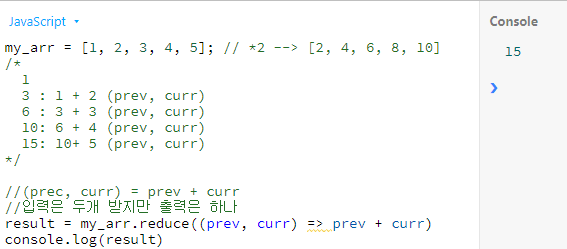
- reduce(python)
# reduce 함수
# functools.py 라는 모듈안에 있는 reduce 함수를 불러오기
from functools import reduce
my_arr = [1, 2, 3, 4, 5]
result = reduce(lambda x, y: x + y, my_arr)
print(result) #15
- 객체 지향 프로그래밍
- class vs instance
<class>
객체(실체) 만들기 위해 template이 있어야함 - template이 class
<instance>
틀에서 찍어내면서 변수에 실제 값이 들어감 --> 인스턴스
runtime시 class로 부터 instance생성됨(값이 실제로 들어가게됨)
실제 값은 object가 만들어지면서 변수방에 runtime시에 들어가게됨
- class
# SoccerPlayer 클래스 선언
class SoccerPlayer(object):
# 생성자 선언 - 객체가 생성될 때 호출되는 메서드
def __init__(self, name, position, back_number):
self.name = name
self.position = position
self.back_number = back_number
# 일반함수 (instance method), back_number값을 입력받아변경하는 함수
# 함수의 첫번째 파라미텅 self가 있어야 클래스에ㅔ 속한 함수가 된다.
# 첫번째 파라미터의 이름은 self가 아니어도 괜찮음
def change(self, new_number):
print(f'선수의 등번호를 변경합니다. From{self.back_number} To {new_number}')
self.back_number = new_number
# toString() 메서드와 동일한 역할
# 객체와 주소가 아니라 객체가 가진 특정 인스턴스 값을 출력
def __str__(self):
return f'My Name is {self.name}, I play in {self.position}'
# 객체 생성
dooly = SoccerPlayer('둘리', 'MF', 10)
# __str__가 있을 경우 자동으로 사용됨
print(dooly) # My Name is 둘리, I play in MF
print('현재 선수의 등번호는 {}'.format(dooly.back_number))#현재 선수의 등번호는 10
dooly.change(99)
print('변경된 선수의 등번호는 {}'.format(dooly.back_number))#변경된 선수의 등번호는 99
# 2차원 리스트를 사용해서 5명의 player 정보를 저장하기
names = ['둘리', '길동', '지성', '홍민', '병근']
positions = ['MF', 'DF', 'cf', 'WF', 'GK']
back_numbers = [10, 15, 20, 30, 1]
# zip 함수
for na, po, nu in zip(names, positions, back_numbers):
print(na, po, nu)
'''
둘리 MF 10
길동 DF 15
지성 cf 20
홍민 WF 30
병근 GK 1
'''
player = [[na, po, nu] for na, po, nu in zip(names, positions, back_numbers)]
print(player)#[['둘리', 'MF', 10], ['길동', 'DF', 15], ['지성', 'cf', 20], ['홍민', 'WF', 30], ['병근', 'GK', 1]]
# SoccerPlayer 클래스 import
from mycode.class_oop.soccer_player import SoccerPlayer
player1 = SoccerPlayer('수녕', 'king', '716')
print(player1)#My Name is 수녕, I play in king
player1.change(7160)
#선수의 등번호를 변경합니다. From716 To 7160
print('----------------------')
players_object = [SoccerPlayer(na, po, nu) for na, po, nu in zip(names, positions, back_numbers)]
print(players_object) #[<mycode.class_oop.soccer_player.SoccerPlayer object at 0x000001E646D1E248>, <mycode.class_oop.soccer_player.SoccerPlayer object at 0x000001E646D1E288>, <mycode.class_oop.soccer_player.SoccerPlayer object at 0x000001E646D1E2C8>, <mycode.class_oop.soccer_player.SoccerPlayer object at 0x000001E646D1E308>, <mycode.class_oop.soccer_player.SoccerPlayer object at 0x000001E646D1E348>]
son = players_object[3]
print(son) #My Name is 홍민, I play in WF
son.name = '호호호'
print(son) #My Name is 호호호, I play in WF
'Python > Python 웹 크롤링' 카테고리의 다른 글
| 파이썬 OpenAPI_07월 21일 (0) | 2020.07.21 |
|---|---|
| 파이썬 OpenAPI_07월 20일 (0) | 2020.07.20 |
| 파이썬 수업_07월 17일 (0) | 2020.07.17 |
| 파이썬 수업_07월15일 (0) | 2020.07.15 |
| 파이썬 설치 및 특징 (0) | 2020.07.14 |