
참고 문서
https://realpython.com/python-requests/
Python’s Requests Library (Guide) – Real Python
In this tutorial on Python's "requests" library, you'll see some of the most useful features that requests has to offer as well as how to customize and optimize those features. You'll learn how to use requests efficiently and stop requests to external serv
realpython.com
- 웹툰 이미지 크롤링
1. 네이버 웹툰 이미지 다운로드
- Referer 라는 header값에 url을 설정한다.
- 특정 image url을 list에 저장한다.
- requests 의 get() 함수로 image data를 요청한다.
- response.content 라는 property를 사용한다.
- local file로 저장한다.
import requests
import os
req_header = {
'referer':'https://comic.naver.com/webtoon/detail.nhn?titleId=626906&no=602&weekday=tue',
}
img_urls = [
'https://image-comic.pstatic.net/webtoon/626906/602/20200720170605_25afe583d26a90598d9dc108ff5f5c98_IMAG01_1.jpg',
'https://image-comic.pstatic.net/webtoon/626906/602/20200720170605_25afe583d26a90598d9dc108ff5f5c98_IMAG01_2.jpg',
'https://image-comic.pstatic.net/webtoon/626906/602/20200720170605_25afe583d26a90598d9dc108ff5f5c98_IMAG01_3.jpg'
]
for img_url in img_urls:
res = requests.get(img_url, headers=req_header)
img_data = res.content
file_name = os.path.basename(img_url)
print(file_name)
with open(file_name,'wb') as file:
print('Writing to {} ({} byte)'.format(file_name, len(img_data)))
file.write(img_data)

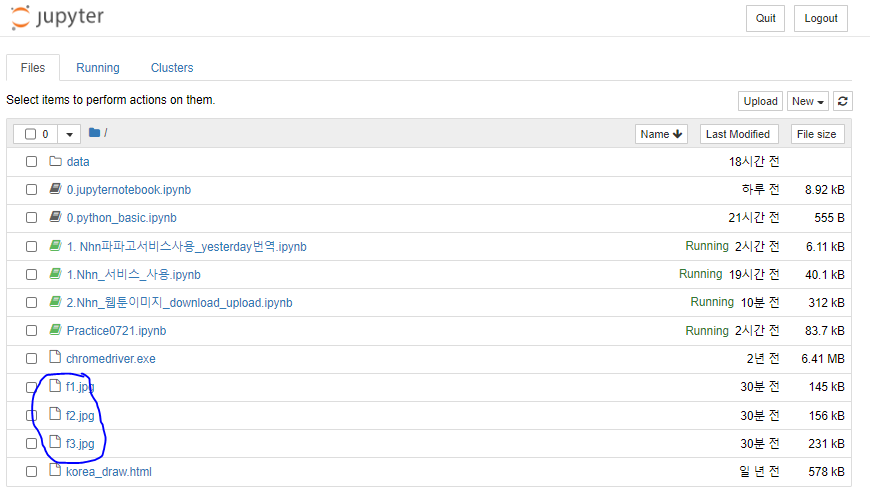
2. 웹툰 이미지 업로드
- https://httpbin.org/post 사이트에 다운받은 img 파일을 업로드
- request의 post() 함수를 사용하고, files속성에 image data 지정한다.
import requests
upload_files_dict = {
'img1':open('f1.jpg','rb'),
'img2':open('f2.jpg','rb'),
'img3':open('f3.jpg','rb')
}
url = 'https://httpbin.org/post'
res = requests.post(url, files=upload_files_dict)
print(res.status_code) #200
img1 = res.json()['files']['img3']
print(img1)

3. 특정 웹툰 페이지 모든 image 다운로드 하기
- soup.select('img[src$=.jpg]')
- img 폴더 생성하고 img 폴더 하위에 파일 저장
import requests
from bs4 import BeautifulSoup
import os
main_url = 'https://comic.naver.com/webtoon/detail.nhn?titleId=626906&no=602&weekday=tue'
res = requests.get(main_url)
html = res.text
soup = BeautifulSoup(html, 'html.parser')
img_urls = []
for img_url in soup.select("img[src$='.jpg']"):
img_urls.append(img_url['src'])
# 디렉토리 생성
if not os.path.isdir('img'):
os.mkdir('img')
for real_url in img_urls:
req_header = {
'referer': main_url
}
res2 = requests.get(real_url, headers=req_header)
img_data = res2.content
file_name = os.path.basename(real_url)
print(file_name)
with open('img/'+file_name,'wb') as file:
print('Writing to {} ({} bytes)'.format(file_name,len(img_data)))
file.write(img_data)


4. 웹툰 메인페이지 스크래핑
- 추천 웹툰의 title과 link를 가져오기
- {title:"한림체육관", link:'www.naver.com'}
- [{title:""},{link:""},{}]
- 웹툰 메인 페이지 > 장르별 추천 웹툰에서 제목, 링크, 이미지 링크를 웹툰별로 뽑아 dict에 저장한 후 list에 저장하기
1) 웹툰 메인 페이지는 아래와 같다.

2) f12 개발자 도구를 이용해 이미지나 제목을 클릭해 html속성을 확인.

3) 소스코드 로직_수녕version
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
main_url = 'https://comic.naver.com/'
res = requests.get(main_url)
html = res.text
soup = BeautifulSoup(html, 'html.parser')
result_map = {}
result_list = []
for a_tag in soup.select("#genreRecommand h6 a"):
link = urljoin(main_url, a_tag['href'].strip())
title = a_tag.text.strip()
result_map={'title':title, 'link':link}
for a_tag in soup.select("#genreRecommand li div a img"):
result_map.update({'img':a_tag['src']})
result_list.append(result_map)
print(result_list)3-1) 소스코드 로직_강사님version
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
main_url = 'https://comic.naver.com/index.nhn'
res = requests.get(main_url)
html = res.text
soup = BeautifulSoup(html, 'html.parser')
print(len(soup.select('#genreRecommand h6 a')))
webtoon_list = []
for a_tag in soup.select('#genreRecommand h6 a'):
title = a_tag.text.strip()
link = urljoin(main_url,a_tag['href'])
#print(title, link)
webtoon_dict = {"title":title, "link":link}
webtoon_list.append(webtoon_dict)
webtoon_list
4) 소스코드 실행한 결과 - list에 map이 들어가있다. _ 수녕version

4-1) 소스코드 실행한 결과_강사님version

5. 특정 웹툰의 image 다운로드 함수로 선언하기
- 웹툰 메인 페이지 > 장르별 추천 웹툰 > 특정 회차 링크 > 해당 링크에 있는 이미지 다운
1) 웹툰 메인 페이지는 아래와같다. 특정 회차란 동그라미친 부분을 말한다.

2) f12 개발자 도구를 이용해 이미지나 제목을 클릭해 html속성을 확인.

3)이미지 저장, 디렉토리 생성 구문이다. 해당 함수에 웹툰 제목과, 이미지를 내려받을 사이트의 링크를 넣어준다._수녕version
import requests
from bs4 import BeautifulSoup
import os
url = 'https://comic.naver.com/'
def write_image(title, main_url):
res = requests.get(main_url)
html = res.text
soup = BeautifulSoup(html, 'html.parser')
img_urls = []
for img_url in soup.select("img[src$='.jpg']"):
img_urls.append(img_url['src'])
# 디렉토리 생성
dir_name = 'img/'+title
if not os.path.isdir(dir_name):
os.mkdir(dir_name)
for real_url in img_urls:
req_header = {
'referer': main_url
}
res2 = requests.get(real_url, headers=req_header)
img_data = res2.content
file_name = os.path.basename(real_url)
print(file_name)
with open(dir_name+'/'+file_name,'wb') as file:
print('Writing to {} ({} bytes)'.format(file_name,len(img_data)))
file.write(img_data)
print(title, main_url)
3-1) 강사님 version
def write_image(title,main_url):
print(title, main_url)
import requests
from bs4 import BeautifulSoup
import os
#main_url= 'https://comic.naver.com/webtoon/detail.nhn?titleId=626906&no=602&weekday=tue'
res = requests.get(main_url)
html = res.text
soup = BeautifulSoup(html, 'html.parser')
img_urls = []
for img_url in soup.select("img[src$='.jpg']"):
#print(img_url)
img_urls.append(img_url['src'])
# 디렉토리 생성
dir_name = 'img/'+ title
if not os.path.isdir(dir_name):
os.mkdir(dir_name)
print(len(img_urls))
for img_url in img_urls:
#print(img_url)
req_header = {
'referer':main_url
}
res2 = requests.get(img_url, headers=req_header)
img_data = res2.content
file_name = os.path.basename(img_url)
with open(dir_name+'/'+file_name,'wb') as file:
print('Writing to {} ({} bytes)'.format(file_name,len(img_data)))
file.write(img_data)
write_image("마음의 소리","https://comic.naver.com/webtoon/detail.nhn?titleId=20853&no=1236")
4) 해당 디렉토리에 인수로 받은 제목으로 디렉토리가 생성되고, 이미지가 다운로드 받아진다.

5) 파라미터를 수동으로 넣는것이 아닌, 특정 회차를 크롤링으로 가져온다._수녕version
from urllib.parse import urljoin
result_list = []
result_dict = {}
for a_tag in soup.select(".genreRecomInfo2"):
for h6 in a_tag.select('h6 a'):
title = h6.text.strip()
result_dict['title'] = title
# print(title)
for p in a_tag.select('p a'):
link = urljoin(url, p['href'])
result_dict['link'] = link
# print(link)
result_list.append(result_dict)
result_dict = {}
print(result_list)
for idx, webtoon in enumerate(result_list):
title = webtoon['title']
detail_link = webtoon['link']
print('----',idx,title,detail_link)
write_image(title,detail_link)5-1) 강사님 version
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
main_url = 'https://comic.naver.com/index.nhn'
res = requests.get(main_url)
html = res.text
soup = BeautifulSoup(html, 'html.parser')
webtoon_list = []
webtoon_dict = {}
for div_tag in soup.select('.genreRecomInfo2'):
#for a_tag1 in div_tag.select('h6 a'):
a_tag1 = div_tag.select('h6 a')[0]
title = a_tag1.text.strip()
link = urljoin(main_url,a_tag1['href'])
#print(title, link)
webtoon_dict["title"]=title
webtoon_dict["link"]=link
#for a_tag2 in div_tag.select('p a'):
a_tag2 = div_tag.select('p a')[0]
detail_link = urljoin(main_url,a_tag2['href'])
print(detail_link)
webtoon_dict["detail_link"]=detail_link
webtoon_list.append(webtoon_dict)
#print(webtoon_list)
webtoon_dict = {}
webtoon_list
for idx,webtoon in enumerate(webtoon_list):
title = webtoon['title']
detail_link = webtoon['detail_link']
print('-----',idx,title, detail_link)
write_image(title,detail_link)
6) 가져와서 dict에 넣은 결과는 다음과 같다._수녕version

6-1) 강사님 version


7) 웹툰 메인페이지에 있는 웹툰 제목별로 특정 회차에 대한 이미지들이 각 폴더에 다운받아진 것을 확인할 수 있다.

** 추가
문자열에 있는 특수문자 제거하는 함수
import re
# 클리닝 함수 (file에 특수문자가 있을 경우 )
def clean_text(text):
text = text.replace("\n", "")
cleaned_text = re.sub('[a-zA-Z]', '', text)
cleaned_text = re.sub('[\{\}\[\]\/?.,;:|\)*~`!^\-_+<>@\#$%&\\\=\(\'\"]',
'', cleaned_text)
return cleaned_text
[출처] Python 프로그래밍|작성자 vega2k
'Python > Python 웹 크롤링' 카테고리의 다른 글
| 파이썬 OpenAPI_07월 23일 (0) | 2020.07.23 |
|---|---|
| 파이썬 OpenAPI_07월 22일 (0) | 2020.07.22 |
| 파이썬 OpenAPI_07월 20일 (0) | 2020.07.20 |
| 파이썬 수업_07월 17일 (0) | 2020.07.17 |
| 파이썬 수업_07월 16일 (0) | 2020.07.16 |